红黑树(red black tree)
- 一个节点标记为红色或者黑色。
- 根是黑色的。
- 如果一个节点是红色的,那么它的子节点必须是黑色的(这就是为什么叫红黑树)。
- 一个节点到到一个null引用的每一条路径必须包含相同数目的黑色节点(所以红色节点不影响)。
其实RB Tree和著名的AVL Tree有很多相同的地方,困难的地方都在于将一个新项插入到树中。了解AVL Tree的朋友应该都知道为了维持树的高度必须在插入一个新的项后必须在树的结构上进行改变,这里主要是通过旋转,当然在RB Tree中原理也是如此。
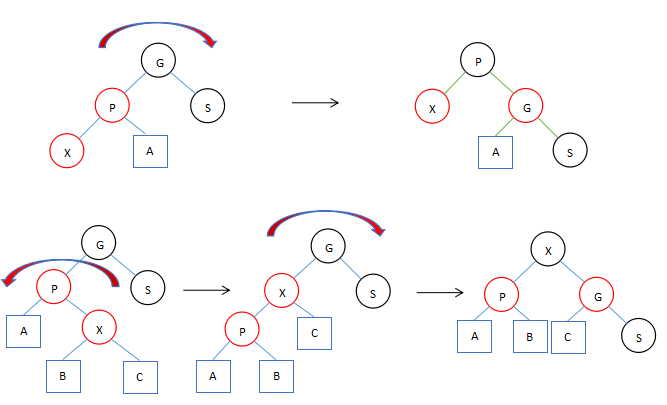
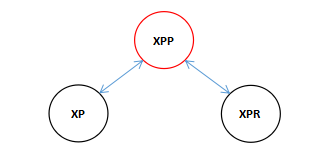
两种旋转和一种典型的变换
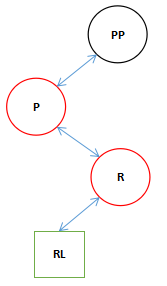
![]() :旋转的方向
:旋转的方向
![]() :交换过程
:交换过程
![]() :互相关联
:互相关联
![]() :单向关联
:单向关联
![]() :代表红色的节点
:代表红色的节点
![]() :代表黑色的节点
:代表黑色的节点
![]() 和
和![]() :代表一个不会破坏红黑树结构的部分,可能是节点,或者是一个子树,总之不会破环当前树的结构。这个部分会由于旋转而连接到其他的节点后面,我们可以理解成由于重力原因它掉到了下面的节点上。
:代表一个不会破坏红黑树结构的部分,可能是节点,或者是一个子树,总之不会破环当前树的结构。这个部分会由于旋转而连接到其他的节点后面,我们可以理解成由于重力原因它掉到了下面的节点上。
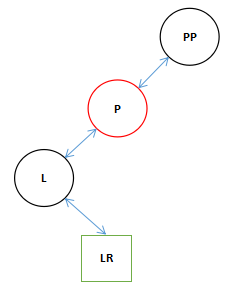
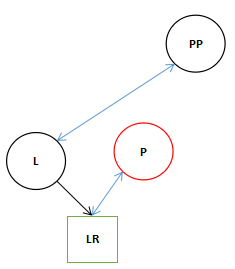
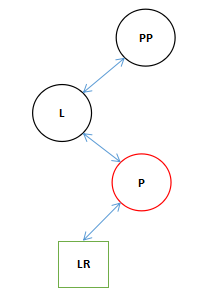
![]()
![]()
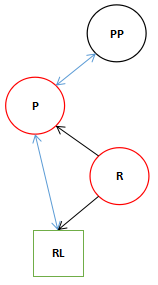
单旋转变换。
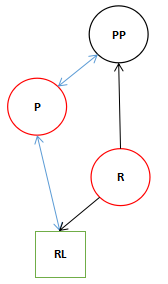
- 双旋转变换(需要两次反方向的单旋转)。
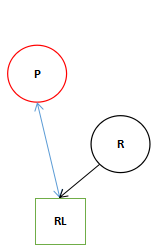
- 当遇到两个子几点都为红色的话执行颜色变换,因为插入 是红色的会产生冲突。如果根节点两边的子节点都是红色,两个叶子节点变成黑色,根节点变成红色,然后再将根节点变成黑色。
上面的图中描述了红黑树中三种典型的变换,其实前两种变换这正是AVL Tree中的两种典型的变换。
几个问题
为什么要进行旋转?
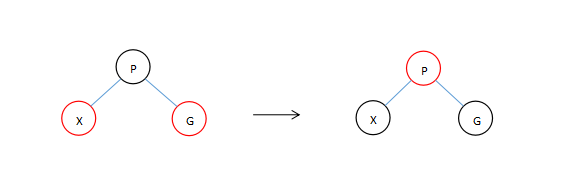
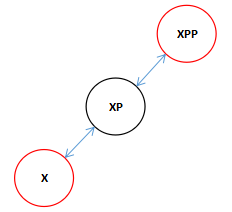
由于P和X节点都为红色节点这破环了红节点下面的节点必须为黑色节点的规则。
新加入的节点总是红色的,这是为什么呢?
因为被插入前的树结构是构建好的,一但我们进行添加黑色的节点,无论添加在哪里都会破坏原有路径上的黑色节点的数量平等关系,所以插入红色节点是正确的选择。
为什么要进行颜色变换?
正如第一种旋转新加入的节点X破坏了红黑树的结构不得不进行旋转,后面的就是旋转后的结果,旋转后形成新的结构,此时我们发现两个子节点都是红色的所以执行第三个变换特性,颜色变换,因为如果子节点是红色的那么我们在添加的时候只能添加黑色的节点,然而添加任何黑色叶子节点都会破坏树的第四条性质,所以要对其进行变换。当进行变换后叶子节点是红色的而且我们默认添加的叶子节点是红色的,所以添加到黑色节点后并不会破坏树的第四条结构,所以这种变换很有用。
第二种双变换中在树的内部怎么出现的红色的节点?
正是由于上面的颜色变换导致新颜色变换后的节点与他的父节点产生了颜色冲突。
与AVL树相比?
比AVL树相比优点是不用在节点类中保存一个节点高度这个变量,节省了内存。
而且红黑树一般不是以递归方式实现的而是以循环的形式实现。
一般的操作在最坏情形下花费O(logN)时间。
HashMap中的代码的实现
putVal方法
所有添加的操作最终都由这个方法完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
{
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else
{
Node<K, V> e;
K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else
{
for (int binCount = 0;; ++binCount)
{
if ((e = p.next) == null)
{
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null)
{
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
上面的方法通过hash计算插入的项的槽位,如果有是一样的key则根据设置的参数是否执行覆盖,如果相应槽位空的话直接插入,如果对应的槽位有项则判断是红黑树结构还是链表结构的槽位,链表的话则顺着链表寻找如果找到一样的key则根据参数选择覆盖,没有找到则链接在链表最后面,链表项的数目大于8则对其进行树化,如果是红黑树结构则按照树的添加方式添加项。
treeifyBin方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| final void treeifyBin(Node<K, V>[] tab, int hash)
{
int n, index;
Node<K, V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null)
{
TreeNode<K, V> hd = null, tl = null;
do
{
TreeNode<K, V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else
{
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
|
找个方法所做的事情就是将刚才九个项以链表的方式连接在一起,然后通过它构建红黑树。
TreeNode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| static final class TreeNode<K, V> extends LinkedHashMap.Entry<K, V>
{
TreeNode<K, V> parent;
TreeNode<K, V> left;
TreeNode<K, V> right;
TreeNode<K, V> prev;
boolean red;
TreeNode(int hash, K key, V val, Node<K, V> next)
{
super(hash, key, val, next);
}
final void treeify(Node<K,V>[] tab)
{
}
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, TreeNode<K,V> x)
{
}
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p)
{
}
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root, TreeNode<K,V> p)
{
}
}
|
可以看出出真正的维护红黑树结构的方法并没有在HashMap中,全部都在TreeNode类内部。
treeify方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| final void treeify(Node<K, V>[] tab)
{
TreeNode<K, V> root = null;
// 以for循环的方式遍历刚才我们创建的链表。
for (TreeNode<K, V> x = this, next; x != null; x = next)
{
// next向前推进。
next = (TreeNode<K, V>) x.next;
x.left = x.right = null;
// 为树根节点赋值。
if (root == null)
{
x.parent = null;
x.red = false;
root = x;
} else
{
// x即为当前访问链表中的项。
K k = x.key;
int h = x.hash;
Class<?> kc = null;
// 此时红黑树已经有了根节点,上面获取了当前加入红黑树的项的key和hash值进入核心循环。
// 这里从root开始,是以一个自顶向下的方式遍历添加。
// for循环没有控制条件,由代码内break跳出循环。
for (TreeNode<K, V> p = root;;)
{
// dir:directory,比较添加项与当前树中访问节点的hash值判断加入项的路径,-1为左子树,+1为右子树。
// ph:parent hash。
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null && (kc = comparableClassFor(k)) == null)
|| (dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
// xp:x parent。
TreeNode<K, V> xp = p;
// 找到符合x添加条件的节点。
if ((p = (dir <= 0) ? p.left : p.right) == null)
{
x.parent = xp;
// 如果xp的hash值大于x的hash值,将x添加在xp的左边。
if (dir <= 0)
xp.left = x;
// 反之添加在xp的右边。
else
xp.right = x;
// 维护添加后红黑树的红黑结构。
root = balanceInsertion(root, x);
// 跳出循环当前链表中的项成功的添加到了红黑树中。
break;
}
}
}
}
// Ensures that the given root is the first node of its bin,自己翻译一下。
moveRootToFront(tab, root);
}
|
第一次循环会将链表中的首节点作为红黑树的根,而后的循环会将链表中的的项通过比较hash值然后连接到相应树节点的左边或者右边,插入可能会破坏树的结构所以接着执行balanceInsertion。
balanceInsertion
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root, TreeNode<K, V> x)
{
x.red = true;
for (TreeNode<K, V> xp, xpp, xppl, xppr;;)
{
if ((xp = x.parent) == null)
{
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left))
{
if ((xppr = xpp.right) != null && xppr.red)
{
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else
{
if (x == xp.right)
{
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null)
{
xp.red = false;
if (xpp != null)
{
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else
{
if (xppl != null && xppl.red)
{
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
} else
{
if (x == xp.left)
{
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null)
{
xp.red = false;
if (xpp != null)
{
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
|
如果您的联想能力很强的话估计到这里应该已经理解这集中变换的主要的关系。
下面简述一下前面的两种种幸运的情况
- x本身为根节点返回x。
- x的父节点为黑色或者x的父节点是根节点直接返回不需要变换。
如若上述两个条件不满足的话,就要进行变换了。
颜色变换
1
2
3
4
5
6
7
8
9
10
11
| if (xp == (xppl = xpp.left))
{
if ((xppr = xpp.right) != null && xppr.red)
{
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
}
|
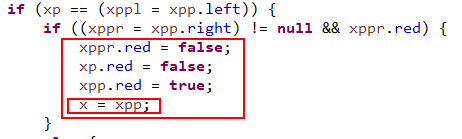
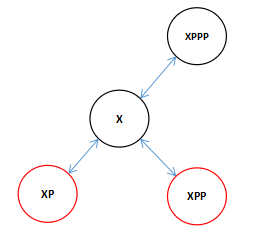
这里是一个典型的一个黑色节点的两个子节点都是红色的所以要进行颜色变换,因为插入的都是红色节点,当检测到祖父节点的左右子节点都是红色的时候两个红色就产生了冲突,所以先将节点进行这种颜色变换,将祖父节点变成红色,然后将祖父的两个子节点变成黑色,这样我们插入的红色节点就不会违背红黑树的规则了。
![]()
![]()
![]()
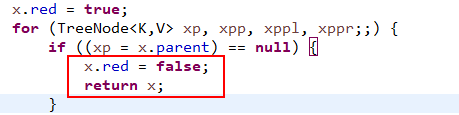
这里有人会有疑问,如果祖父节点是根节点呢,那样的话祖父节点也会变成黑色,因为每次循环进行插入平衡的操作当进行这种颜色变换之后都会将插入节点的引用指向祖父节点,当进行下一轮循环的时候会优先检测当前节点是否是根节点,如果是根节点那就将颜色变成黑色,下面看图:
![]()
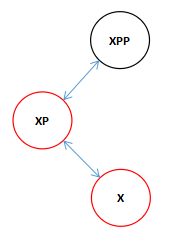
当将节点指向祖父节点进行下一轮循环时:
![]()
两个核心旋转(左旋转和右旋转)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
if (xp == (xppl = xpp.left))
{
if ((xppr = xpp.right) != null && xppr.red)
{
}
else
{
if (x == xp.right)
{
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null)
{
xp.red = false;
if (xpp != null)
{
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
|
颜色变换完成后进入下面的else块
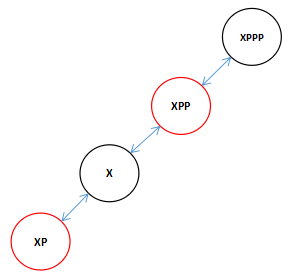
我们已知xp是xpp的左节点,首先判断了x是xp的左节点还是右节点,如果是右节点的话构成了下面的结构。
![]()
这中结构需要进行双旋转,首先先进行一次向左旋转。
左旋转
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static <K, V> TreeNode<K, V> rotateLeft(TreeNode<K, V> root, TreeNode<K, V> p)
{
TreeNode<K, V> r, pp, rl;
if (p != null && (r = p.right) != null)
{
if ((rl = p.right = r.left) != null)
rl.parent = p;
if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
else if (pp.left == p)
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
return root;
}
|
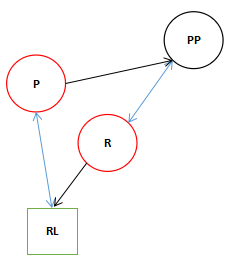
- 刚进入方法时,状态如下图。(RL可能是空的)
![]()
- 进入了if块后执行到第10行后。
1
2
| if ((rl = p.right = r.left) != null)
rl.parent = p;
|
![]()
![]()
![]()
此时如果9行的条件符合的话执行10行RL指向P,如果RL为null的话,P的右节点指向null。
3. 接着看11和12行代码。
1
2
| if ((pp = r.parent = p.parent) == null)
(root = r).red = false;
|
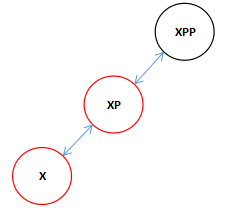
首先我们看11行if里面的赋值语句所造成的影响。
![]()
![]()
![]()
在if里面的表达式不管符不符合条件()内的内容都会执行。
如果符合条件的话会执行12行的代码,变成了下面的结果。
![]()
![]()
![]()
由于PP为空所以只剩下这三个。
4. 如果11行的条件为假的话,执行完11行()内的表达式后执行13行
1
2
| else if (pp.left == p)
pp.left = r;
|
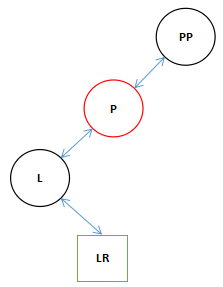
![]()
![]()
![]()
满足条件的话R和PP互相关联。
5. 由于进入了13和14行所以不进入15和16行的else语句。
- 看17和18行。
1
2
| r.left = p;
p.parent = r;
|
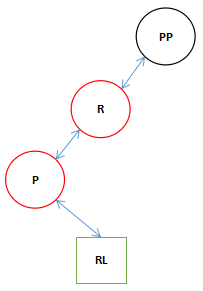
![]()
![]()
![]()
最终执行完了一个旋转变成了我们开始说的第一种旋转的形式,这个结构还需要向右旋转一次。
1
2
3
4
5
| if (x == xp.right)
{
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
|
1
| xpp = (xp = x.parent) == null ? null : xp.parent;
|
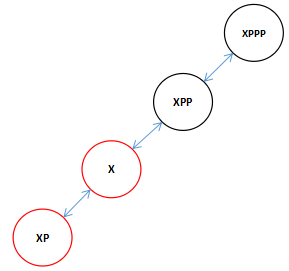
执行完上面的代码,旋转后调整x,xp,和xpp的关系得到下图。
![]()
右旋转
1
2
3
4
5
6
7
8
9
| if (xp != null)
{
xp.red = false;
if (xpp != null)
{
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
|
- 首先让XP变成黑色。
![]()
- 如果XPP不为空的话变成红色。
![]()
由于我们在rotateLeft(root, xpp),传进来的是XXP所以下面的的旋转中实际上就是对XP和XXP执行了一次与上面的方向相反其他完全相同的旋转。
接着我们看向右旋转的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static <K, V> TreeNode<K, V> rotateRight(TreeNode<K, V> root, TreeNode<K, V> p)
{
TreeNode<K, V> l, pp, lr;
if (p != null && (l = p.left) != null)
{
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
|
- 刚进来的时候结构是这个样子。
![]()
在这里的P就是刚才传进来的XPP。 - 这里我们认为LR是存在的,其实这个不影响主要的旋转,为空就指向null呗,直接执行完9和10行。
1
2
| if ((lr = p.left = l.right) != null)
lr.parent = p;
|
![]()
![]()
![]()
5. 在这里我们假使PP是存在的,直接执行完11的表达式不再执行12行。(不再分析不存在的情况)。
1
2
| if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
|
![]()
![]()
![]()
6. 由于11行的条件不符合,现在直接执行13行的表达式,不符合执行15行else,执行16行。
![]()
![]()
![]()
7. 最后执行层17和18行。
1
2
| l.right = p;
p.parent = l;
|
![]()
![]()
![]()
最终完成两次的旋转。
疑问
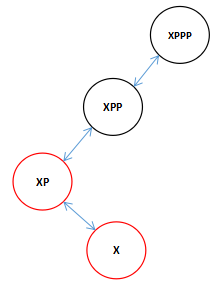
大家可能觉得和刚才接不上其实是这样的,刚才在右旋转前的时候的图像是这个样的。
![]()
因为我们传进来的是XPP,所以结合上一次的向左旋转我们在向右旋转的时候看到全图应该是这个样子的。(注:XPPP可能是XPP的左父节点也可能是右父节点这里不影响,而且可以是任意颜色)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
现在知道为什么XPPP可以是任意颜色的了吧,因为旋转过后X是黑色的即便XPPP是红色,此时我们又可以对两个红色的子节点进行颜色变换了,变换后X和XPPP有发生了颜色冲突,接着进行旋转直到根
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root, TreeNode<K, V> x)
{
x.red = true;
for (TreeNode<K, V> xp, xpp, xppl, xppr;;)
{
if ((xp = x.parent) == null)
{
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left))
{
}
else
{
}
}
}
|
、分析了插入位置父节点在祖父节点的左边的情况,并没有分析另外一面的对称情况,其实是一样的因为调用的都是相同的方法。
以上就是在1.8中的HashMap新引进的红黑树树化的过程,与原来的链表相比当同一个bucket上存储很多entry的话树形的查找结构明显要比链表线性的的效率要高。
 :旋转的方向
:旋转的方向 :交换过程
:交换过程 :互相关联
:互相关联 :单向关联
:单向关联 :代表红色的节点
:代表红色的节点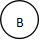 :代表黑色的节点
:代表黑色的节点 和
和 :代表一个不会破坏红黑树结构的部分,可能是节点,或者是一个子树,总之不会破环当前树的结构。这个部分会由于旋转而连接到其他的节点后面,我们可以理解成由于重力原因它掉到了下面的节点上。
:代表一个不会破坏红黑树结构的部分,可能是节点,或者是一个子树,总之不会破环当前树的结构。这个部分会由于旋转而连接到其他的节点后面,我们可以理解成由于重力原因它掉到了下面的节点上。