性能调优--Tomcat
整体架构

Server(服务器)是Tomcat构成的顶级构成元素,所有一切均包含在Server中,Server的实现类StandardServer可以包含一个到多个Services,Service的实现类为StandardService调用了容器(Container)接口,其实是调用了Servlet Engine(引擎),而且StandardService类中也指明了该Service归属的Server;
Container: 引擎(Engine)、主机(Host)、上下文(Context)和Wraper均继承自Container接口,所以它们都是容器。但是,它们是有父子关系的,在主机(Host)、上下文(Context)和引擎(Engine)这三类容器中,引擎是顶级容器,直接包含是主机容器,而主机容器又包含上下文容器,所以引擎、主机和上下文从大小上来说又构成父子关系,虽然它们都继承自Container接口。
连接器(Connector)将Service和Container连接起来,首先它需要注册到一个Service,它的作用就是把来自客户端的请求转发到Container(容器),这就是它为什么称作连接器的原因。
概述
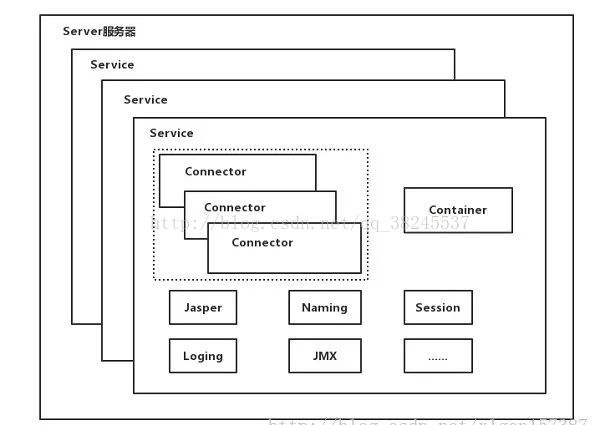
Tomcat中最顶层的容器是Server,代表着整个服务器,从上图中可以看出,一个Server可以包含至少一个Service,用于具体提供服务。
Service主要包含两个部分:Connector和Container。从上图中可以看出 Tomcat 的心脏就是这两个组件,他们的作用如下:
1、Connector用于处理连接相关的事情,并提供Socket与Request和Response相关的转化; 2、Container用于封装和管理Servlet,以及具体处理Request请求;
一个Tomcat中只有一个Server,一个Server可以包含多个Service,一个Service只有一个Container,但是可以有多个Connectors,这是因为一个服务可以有多个连接,如同时提供Http和Https链接,也可以提供向相同协议不同端口的连接,示意图如下(Engine、Host、Context下边会说到):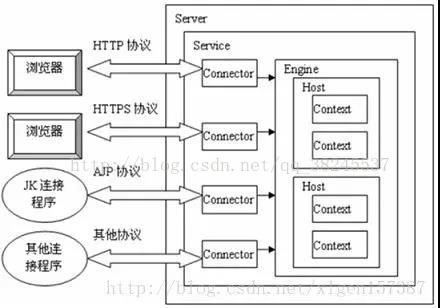
多个 Connector 和一个 Container 就形成了一个 Service,有了 Service 就可以对外提供服务了,但是 Service 还要一个生存的环境,必须要有人能够给她生命、掌握其生死大权,那就非 Server 莫属了!所以整个 Tomcat 的生命周期由 Server 控制。
另外,上述的包含关系或者说是父子关系,都可以在tomcat的conf目录下的server.xml配置文件中看出,下图是删除了注释内容之后的一个完整的server.xml配置文件(Tomcat版本为8.0)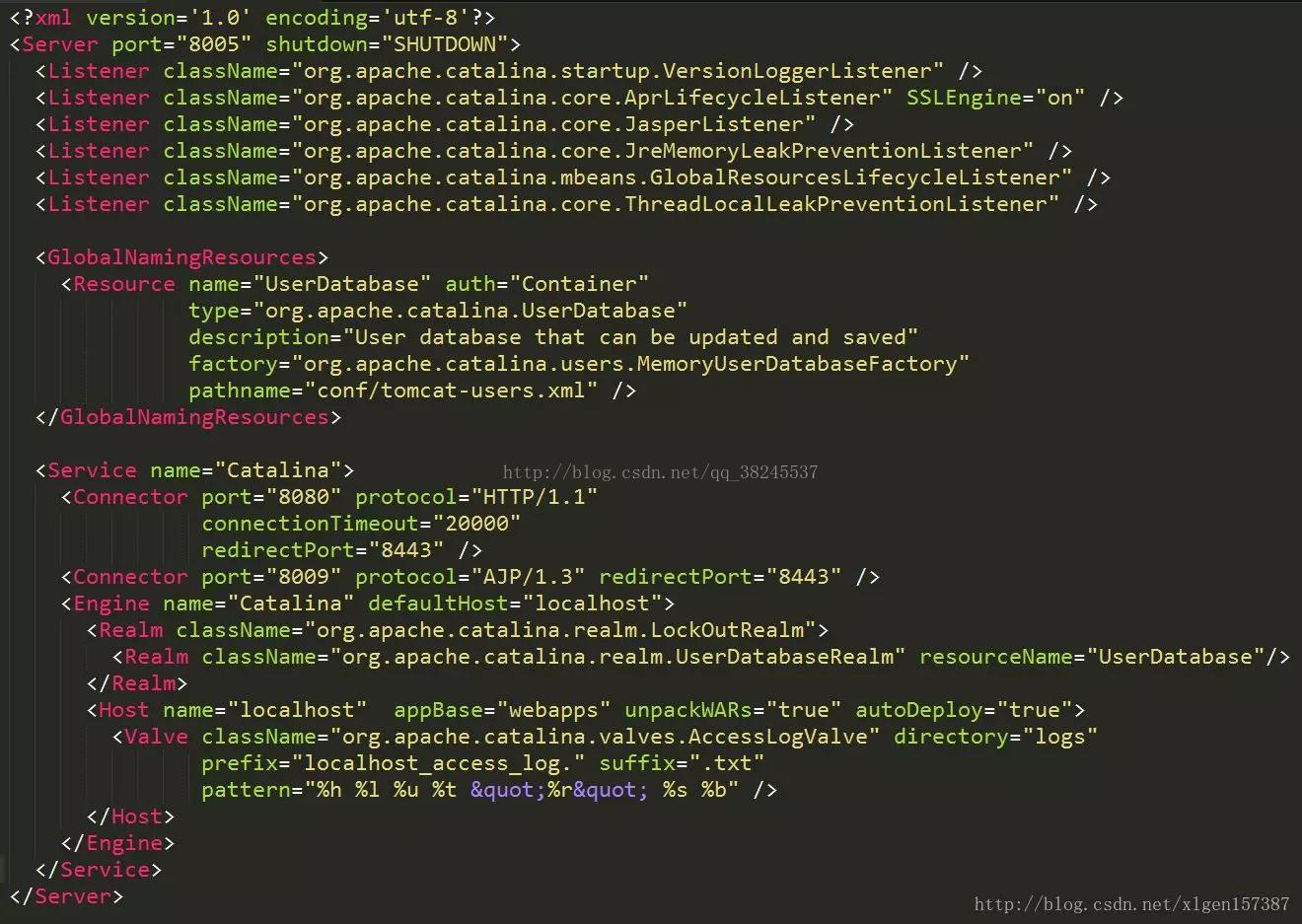
上边的配置文件,还可以通过下边的一张结构图更清楚的理解: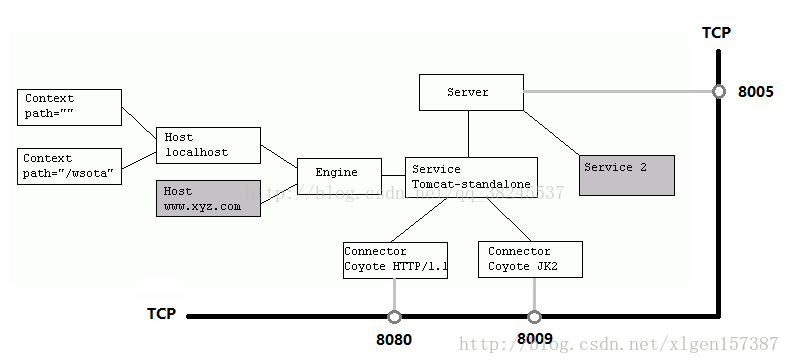
Server标签设置的端口号为8005,shutdown=”SHUTDOWN” ,表示在8005端口监听“SHUTDOWN”命令,如果接收到了就会关闭Tomcat。一个Server有一个Service,当然还可以进行配置,一个Service有多个,Service左边的内容都属于Container的,Service下边是Connector。
总结
- Tomcat中只有一个Server,一个Server可以有多个Service,一个Service可以有多个Connector和一个Container;
- Server掌管着整个Tomcat的生死大权;
- Service 是对外提供服务的;
- Connector用于接受请求并将请求封装成Request和Response来具体处理;
- Container用于封装和管理Servlet,以及具体处理request请求;
Connector和Container的微妙关系
由上述内容我们大致可以知道一个请求发送到Tomcat之后,首先经过Service然后会交给我们的Connector,Connector用于接收请求并将接收的请求封装为Request和Response来具体处理,Request和Response封装完之后再交由Container进行处理,Container处理完请求之后再返回给Connector,最后在由Connector通过Socket将处理的结果返回给客户端,这样整个请求的就处理完了!
Connector最底层使用的是Socket来进行连接的,Request和Response是按照HTTP协议来封装的,所以Connector同时需要实现TCP/IP协议和HTTP协议!
Tomcat既然处理请求,那么肯定需要先接收到这个请求,接收请求这个东西我们首先就需要看一下Connector!
Connector架构分析
Connector用于接受请求并将请求封装成Request和Response,然后交给Container进行处理,Container处理完之后在交给Connector返回给客户端。
因此,我们可以把Connector分为四个方面进行理解:
(1)Connector如何接受请求的? (2)如何将请求封装成Request和Response的? (3)封装完之后的Request和Response如何交给Container进行处理的? (4)Container处理完之后如何交给Connector并返回给客户端的?
首先看一下Connector的结构图(图B),如下所示:
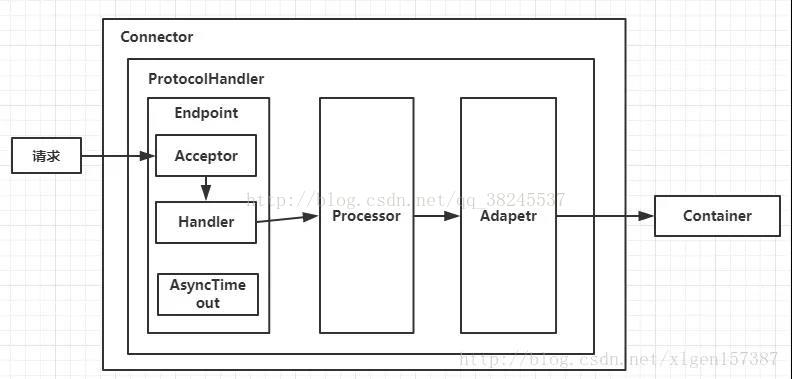
Connector就是使用ProtocolHandler来处理请求的,不同的ProtocolHandler代表不同的连接类型,比如:Http11Protocol使用的是普通Socket来连接的,Http11NioProtocol使用的是NioSocket来连接的。
其中ProtocolHandler由包含了三个部件:Endpoint、Processor、Adapter。
(1)Endpoint用来处理底层Socket的网络连接,Processor用于将Endpoint接收到的Socket封装成Request,Adapter用于将Request交给Container进行具体的处理。
(2)Endpoint由于是处理底层的Socket网络连接,因此Endpoint是用来实现TCP/IP协议的,而Processor用来实现HTTP协议的,Adapter将请求适配到Servlet容器进行具体的处理。
(3)Endpoint的抽象实现AbstractEndpoint里面定义的Acceptor和AsyncTimeout两个内部类和一个Handler接口。Acceptor用于监听请求,AsyncTimeout用于检查异步Request的超时,Handler用于处理接收到的Socket,在内部调用Processor进行处理。
至此,我们应该很轻松的回答(1)(2)(3)的问题了,但是(4)还是不知道,那么我们就来看一下Container是如何进行处理的以及处理完之后是如何将处理完的结果返回给Connector的?
Container架构分析
Container用于封装和管理Servlet,以及具体处理Request请求,在Connector内部包含了4个子容器,结构图如下(图C):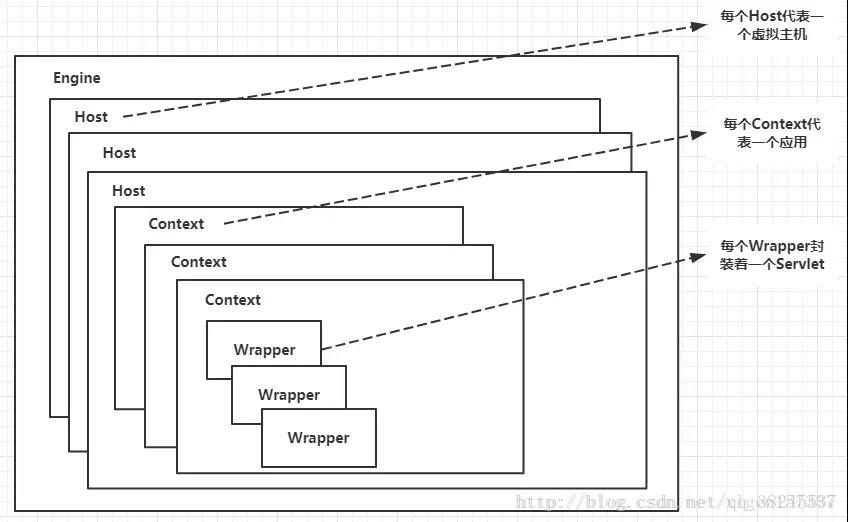
个子容器的作用分别是:
(1)Engine:引擎,用来管理多个站点,一个Service最多只能有一个Engine; (2)Host:代表一个站点,也可以叫虚拟主机,通过配置Host就可以添加站点; (3)Context:代表一个应用程序,对应着平时开发的一套程序,或者一个WEB-INF目录以及下面的web.xml文件; (4)Wrapper:每一Wrapper封装着一个Servlet;
下面找一个Tomcat的文件目录对照一下,如下图所示: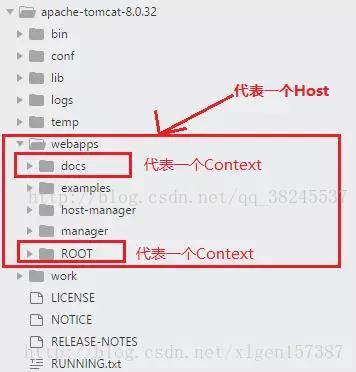
Context和Host的区别是Context表示一个应用,我们的Tomcat中默认的配置下webapps下的每一个文件夹目录都是一个Context,其中ROOT目录中存放着主应用,其他目录存放着子应用,而整个webapps就是一个Host站点。
我们访问应用Context的时候,如果是ROOT下的则直接使用域名就可以访问,例如:www.ledouit.com,如果是Host(webapps)下的其他应用,则可以使用www.ledouit.com/docs进行访问,当然默认指定的根应用(ROOT)是可以进行设定的,只不过Host站点下默认的主营用是ROOT目录下的。
看到这里我们知道Container是什么,但是还是不知道Container是如何进行处理的以及处理完之后是如何将处理完的结果返回给Connector的?别急!下边就开始探讨一下Container是如何进行处理的!
Container如何处理请求的
Container处理请求是使用Pipeline-Value管道来处理的!
Pipeline-Value是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将处理后的请求返回,再让下一个处理着继续处理。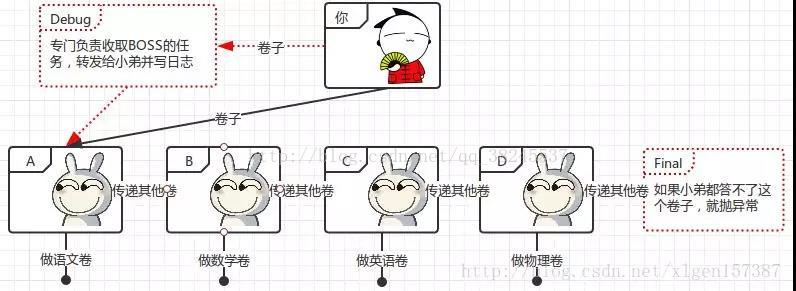
但是!Pipeline-Value使用的责任链模式和普通的责任链模式有些不同!区别主要有以下两点:
(1)每个Pipeline都有特定的Value,而且是在管道的最后一个执行,这个Value叫做BaseValue,BaseValue是不可删除的;(2)在上层容器的管道的BaseValue中会调用下层容器的管道。
我们知道Container包含四个子容器,而这四个子容器对应的BaseValue分别在:StandardEngineValue、StandardHostValue、StandardContextValue、StandardWrapperValue。
Pipeline的处理流程图如下(图D):
1)Connector在接收到请求后会首先调用最顶层容器的Pipeline来处理,这里的最顶层容器的Pipeline就是EnginePipeline(Engine的管道);
(2)在Engine的管道中依次会执行EngineValue1、EngineValue2等等,最后会执行StandardEngineValue,在StandardEngineValue中会调用Host管道,然后再依次执行Host的HostValue1、HostValue2等,最后在执行StandardHostValue,然后再依次调用Context的管道和Wrapper的管道,最后执行到StandardWrapperValue。
(3)当执行到StandardWrapperValue的时候,会在StandardWrapperValue中创建FilterChain,并调用其doFilter方法来处理请求,这个FilterChain包含着我们配置的与请求相匹配的Filter和Servlet,其doFilter方法会依次调用所有的Filter的doFilter方法和Servlet的service方法,这样请求就得到了处理!
(4)当所有的Pipeline-Value都执行完之后,并且处理完了具体的请求,这个时候就可以将返回的结果交给Connector了,Connector在通过Socket的方式将结果返回给客户端。
conf目录

lib目录
logs目录

webapp目录和部署web应用
简化web应用部署的方式,但是建议使用外置目录的方式
放置在webapp方式
直接拖过去
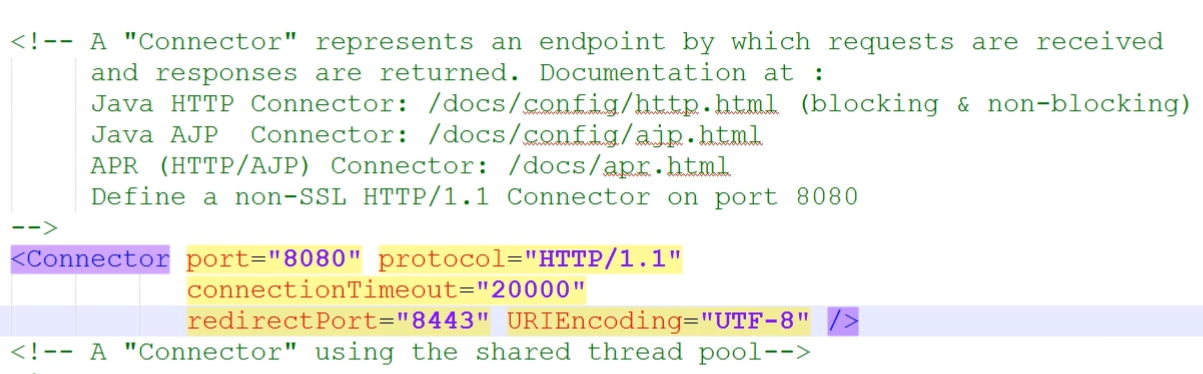
修改conf/server.xml

该方法不支持动态部署,建议在生产环境使用,
独立的Context.xml文件

该方式可以实现热部署、热加载,直接修改文件即可及时生效,所以建议在开发环境使用
I/O连接器
官方文档
相应xml配置属性对应Connector.java
问题
独立Context.xml如果配置path的话,是以文件名为主 还是 以配置的为主
以文件名为主,设置path属性是无效的,如果要设置根路径,则修改文件名为Root.xml即可
根独立context.xml配置文件路径

如果实现热部署

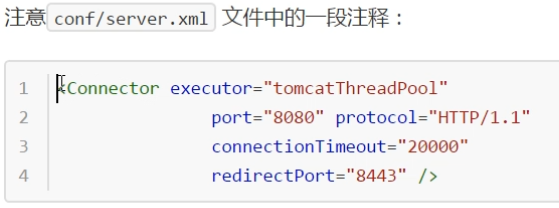
连接器里面的连接池是用的那个线程池


tomcat中文乱码问题


JNDI


digester
tomcat中使用的digester做xml和bean的映射的
嵌入式Tomcat

Web技术栈
servlet

web flux (Netty)
Tomcat Maven插件


Tomcat7RunnerCli
Tomcat7 API编程
确定classPath路径

创建Tomcat实例


设置host对象

设置classPath

设置context
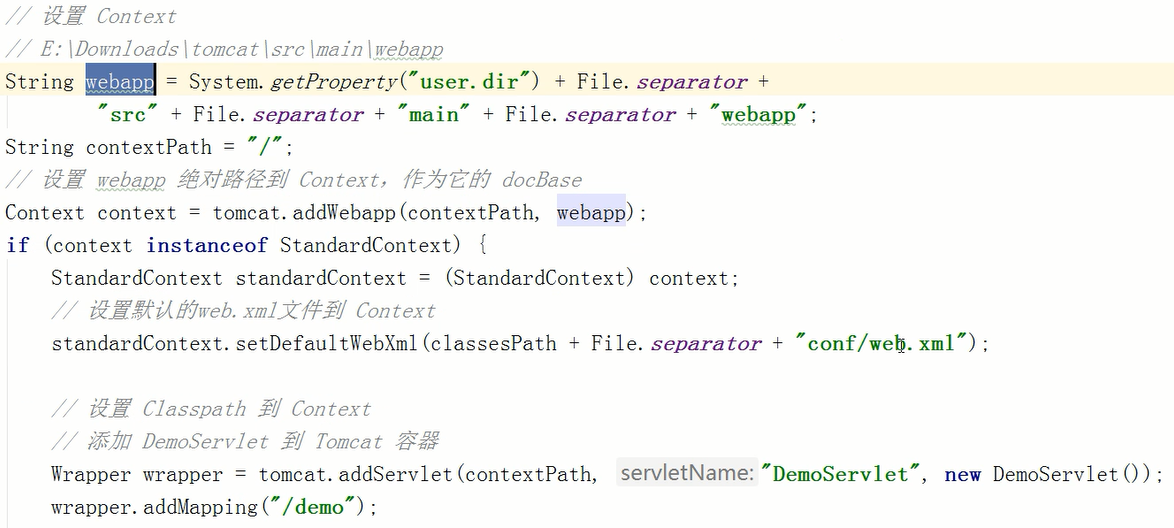
设置service

设置Servlet

spring boot

自定义Context
实现TomcatContextCustomizer

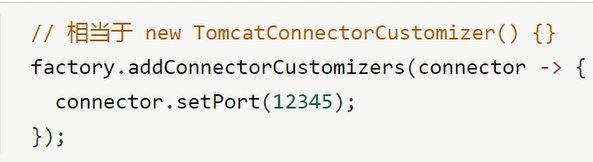
自定义Connector
实现TomcatConectorCustomizer
调优
Tomcat调优
减配优化
conf/web.xml作为Servlet应用默认的web.xml,实际上,应用程序有两个web.xml, 其中包括应用的web.xml,最终将两者合并。
不需要jsp
移除Servlet
分析:不需要资源的,包括动态和静态
如果当前应用是微服务Rest应用
- 静态:DefaultServlet
- 优化方案:通过移除conf/web.xml中
org.apache.catalina.servlets.DefaultServlet
- 优化方案:通过移除conf/web.xml中
DefaultServlet: Tomcat处理静态资源的servlet
- 动态:JspServlet
- 优化方案:通过移除conf/web.xml中的
org.apache.jasper.servlet.JspServlet
- 优化方案:通过移除conf/web.xml中的
DispatcherServlet: Spring Web Mvc应用Servlet
JspServlet: 编译并且执行jsp页面
移除 welcome-file-list

因为他要去查找这些文件,如果业务不需要的话,就不要使用
删减Mime-mapping
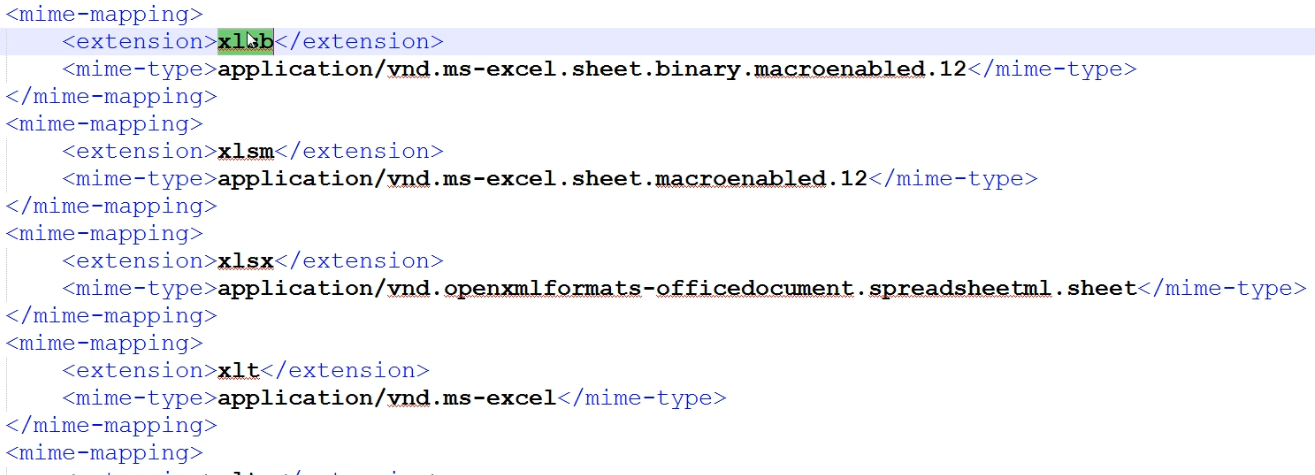 web.xml中有大量的mime-mapping配置,根据具体的业务情况作出一些删减
web.xml中有大量的mime-mapping配置,根据具体的业务情况作出一些删减
移除session设置 或者 设置-1
对于微服务REST应用,不需要Session, 因为不需要状态
替代方案:OAuth2.0、JWT
session通过JSessionid进行用户跟踪,因为http无状态,需要一个id与当前用户会话联系,spring session 使用jsession id作为redis,实现多个机器登录,用户会话不丢失。
现在的session已经用户不大,如果业务用不到的话,就删除掉
移除Valve
Valve类似于Filter
比如移除AccessLongValve, 可以通过nginx的AccessLog替代,Valve实现都需要消耗java应用的计算时间。最外层已经有了AccessLog,内部服务意义不是很大。
需要jsp
分析:JspServlet是无法移除的,了解JspServlet处理原理
JsPServlet 相关ServletConfig参数优化
需要编译时
- compile 编译器
- modificationTestLnterval 是否需要动态编译
不需要编译
- development 开发阶段设置成false
development=false, 那么jsp要如何去编译呢?游湖方法
- Ant Task执行Jsp编译
- Maven插件:org.codehaus.mojo:JSPC-maven-plugin
JspServlet 如果development参数为true,他会自行检查文件是否修改,如果修改重新翻译,在编译、加载和执行,言外之意,jspServle开发模式可能会导致OOM,卸载class不及时所导致老年代(JDK 7)区域不够。
ClassLoader -> a.class b.class c.class
ChildClassLoader -> d.class e.class
1.class需要卸载,需要将ParentClassLoader设置成null, 当ClassLoader被GC后, 1-3 class全部会被卸载。
class是个文件,文件被JVM加载,二进制-> Verify->解析
配置调整
关闭自动重载
通过修改context.xml
修改连接线程池数量
通过修改server.xml
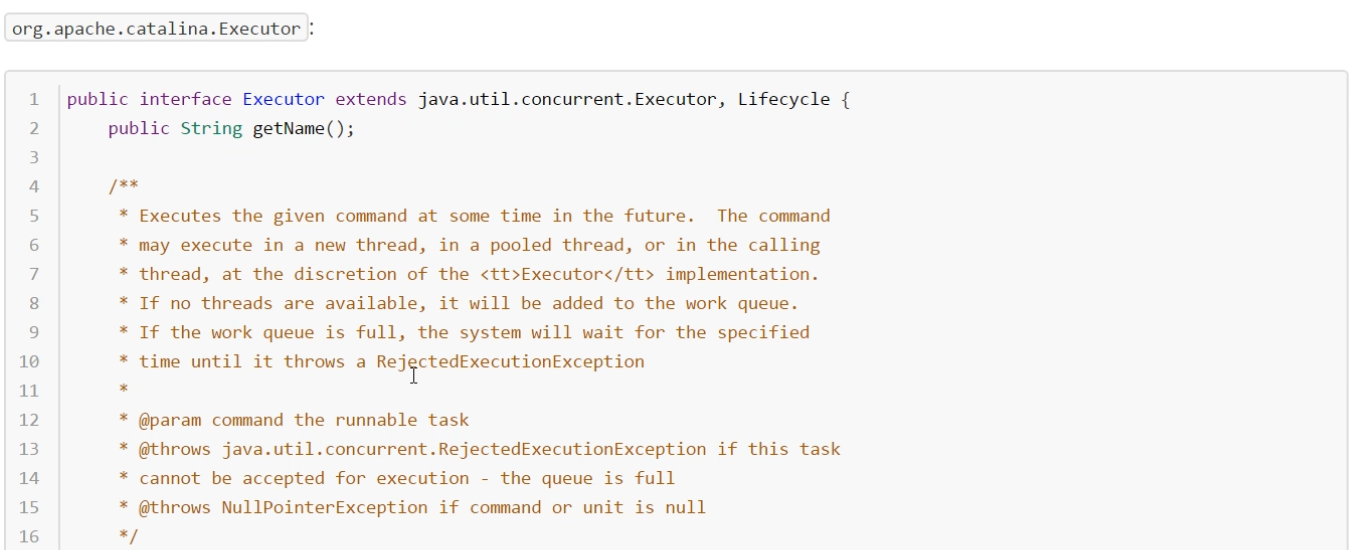
Executor 实际上Tomcat接口org.apache.catalina.Executor
扩展了 juc中的接口java.util.concurrent.Executor
实现org.apache.catalina.core.StandardThreadExecutor
线程池org.apache.tomcat.util.threads.ThreadPoolExecutor(java.util.concurrent.ThreadPoolExecutor)
通过JMX修改
观察StandardThreadExecutor是否存在调整线程池数量的API
评估一些参考:
- 正确率
- Load(cpu和jvm gc)
- TPS/QPS(越大越好)
- CPU密集型(加密/解密、算法)
- IO密集型:网络、文件读写等
到底设置多少线程数量才是最优
- 评估整体的请求量,假设100W QPS, 有机器数量100台,每台支撑1WQPS。
- 进行压力测试,需要一些测试样本,JMeter等实现,假设一次请求需要RT 10毫秒,1表可以完成100个请求。10000/100=100线程,一般而言,load不要太高,要减少Full GC, GC取决于JVM堆大小。执行一次操作需要5MB内存,则需要50GB,实际上只有20GB,必然执行GC,则需要程序调优,首先最好对象外化(比如redis,同时又需要评估Redis网络开销,又要评估网卡的接受能力)
- 常规性的压测,由于业务的变更,会导致底层性能变化。
预编译优化
jsp
- Ant Task执行Jsp编译
- Maven插件:org.codehaus.mojo:JSPC-maven-plugin
程序调优
参考问题:到底设置多少线程数量才是最优?
JVM优化
如果JVM版本小于9,默认ParallelGC
如果是JVM 9, 默认G1
调整GC算法
模式切换
