性能调优--MySQL
架构图

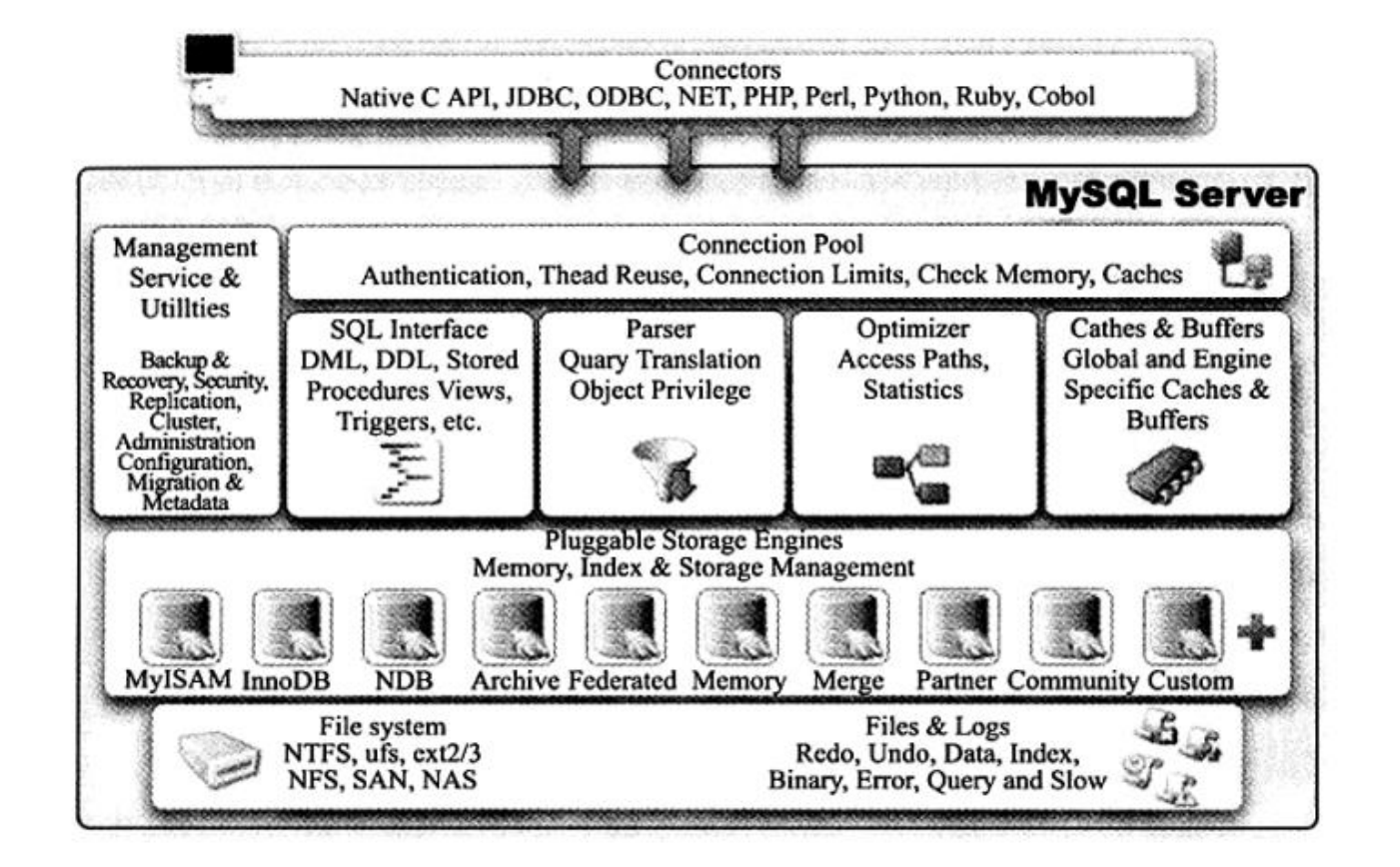
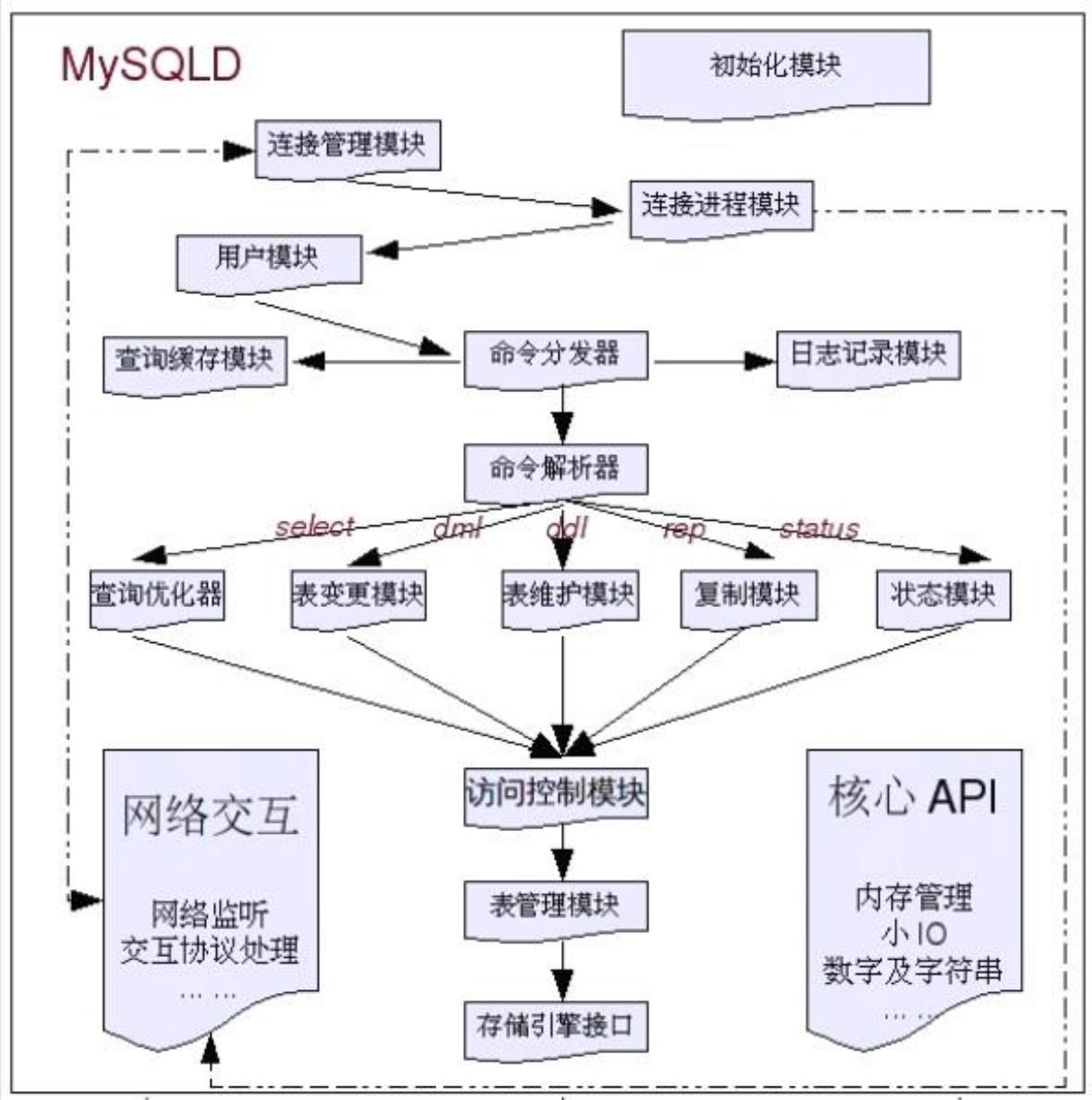
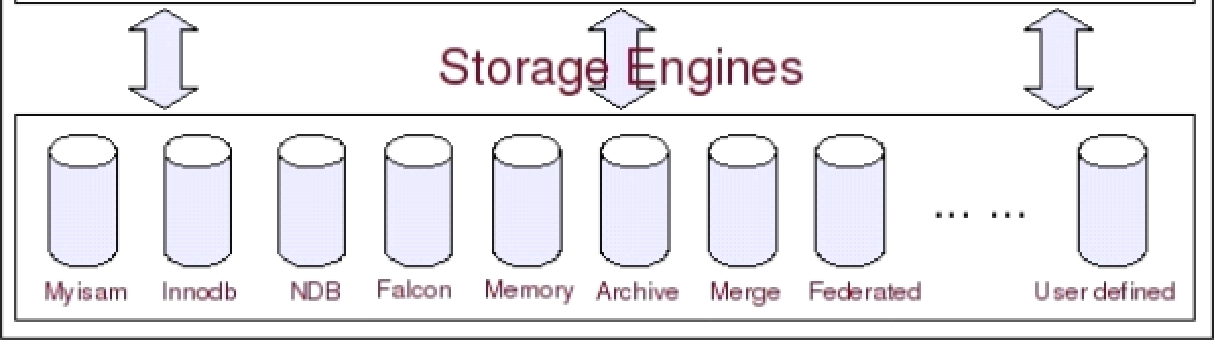
存储引擎
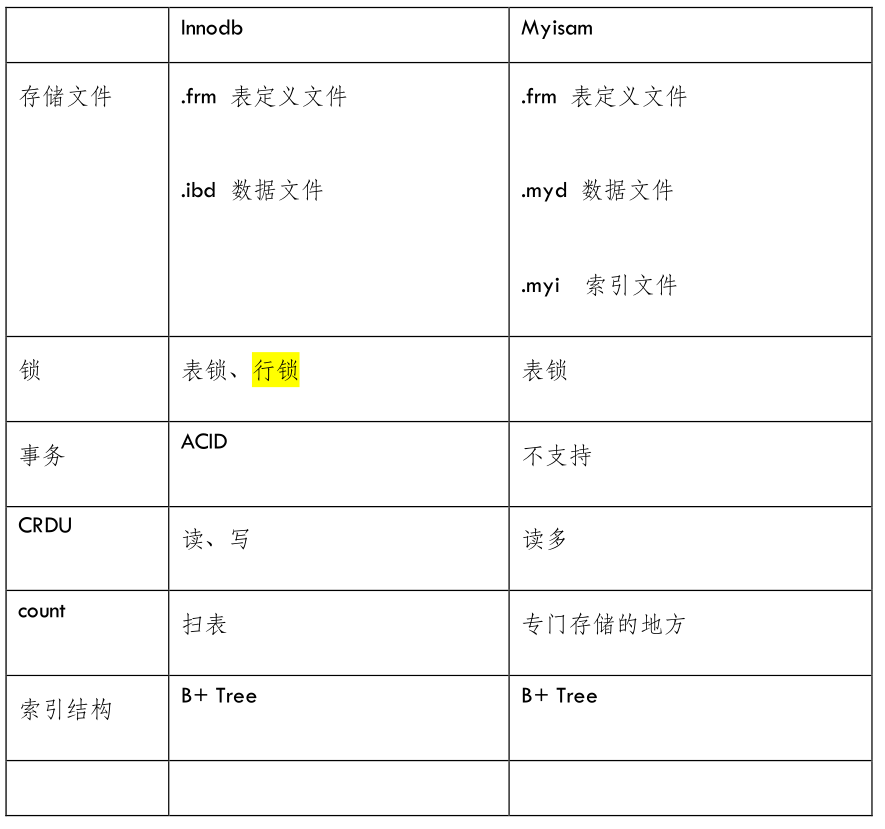
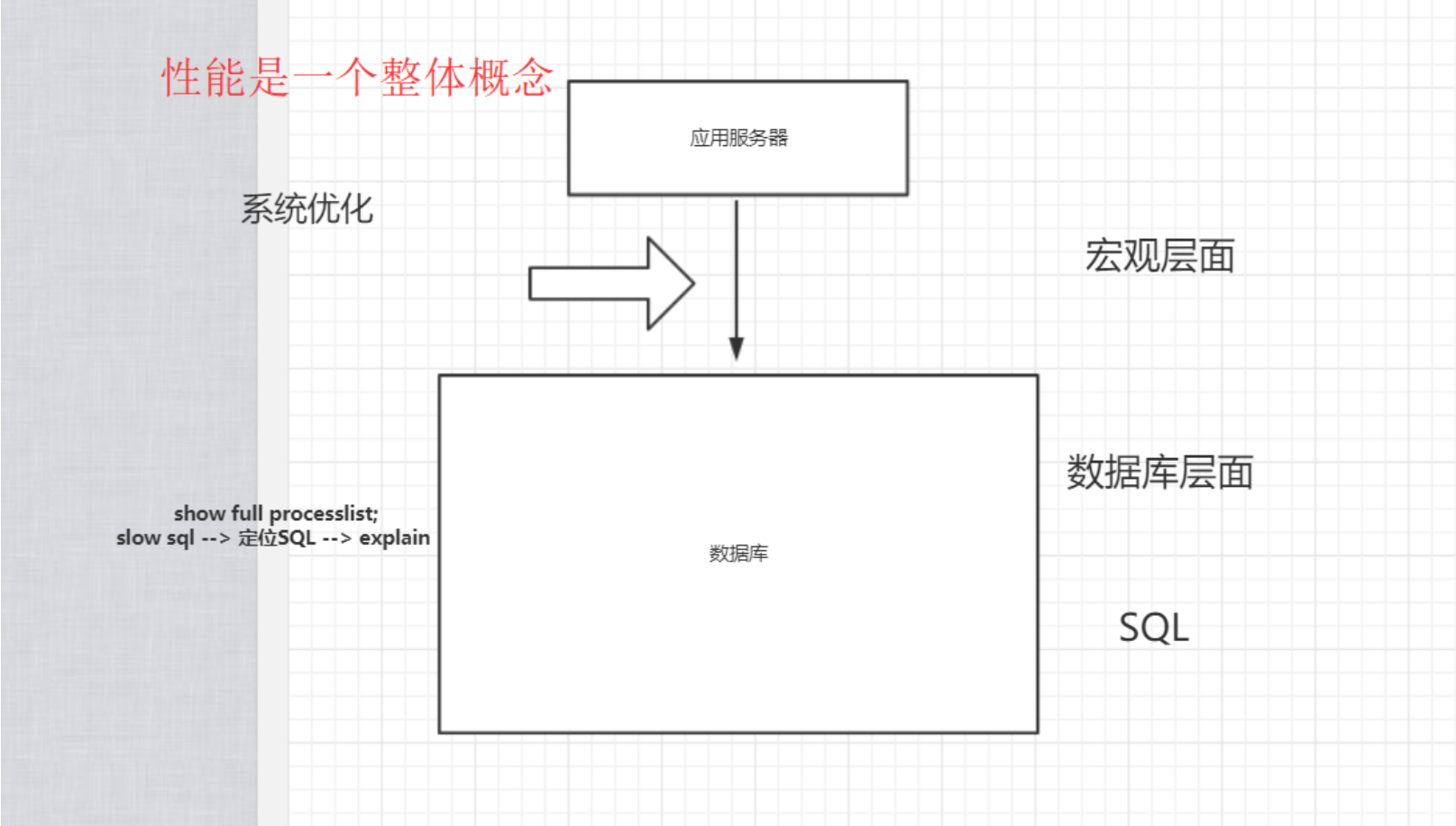
性能
影响性能的因素
人为因素-需求
- 大数据量 count(*)
- 实时、准实时、有误差
程序员因素-面向对象

缓存cache
缓存不可用
对可扩展过度追求
字段过于冗余
表范式
太按照范式建表
应用场景
OLTP
online Transaction Processioning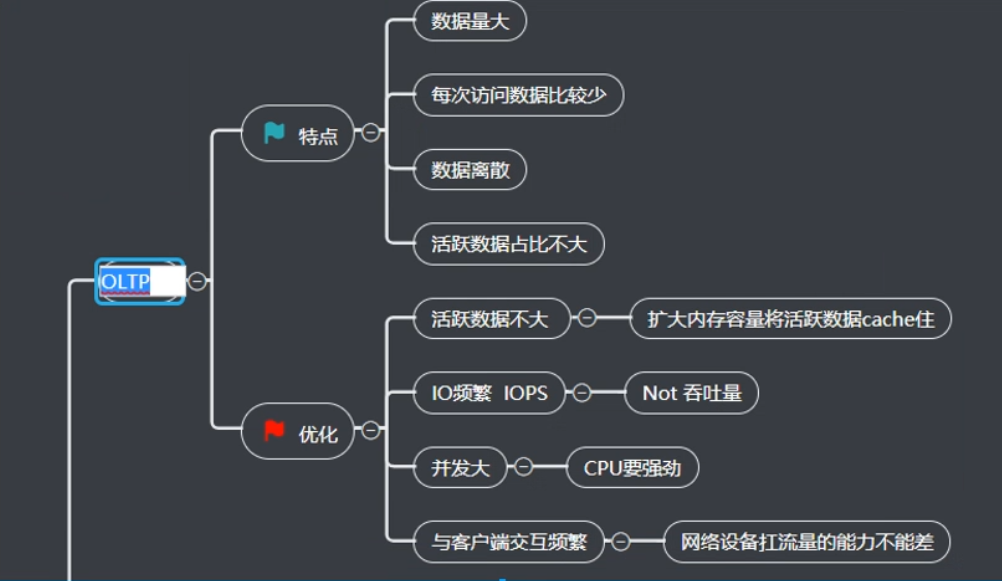
OLAP
Online analysis Processing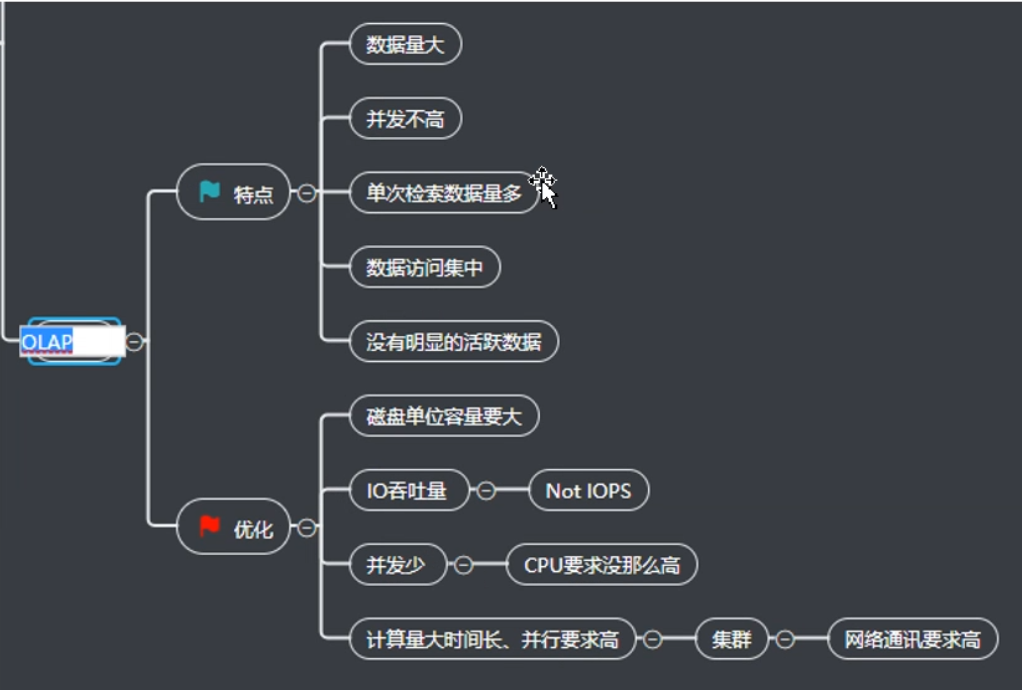
提高性能
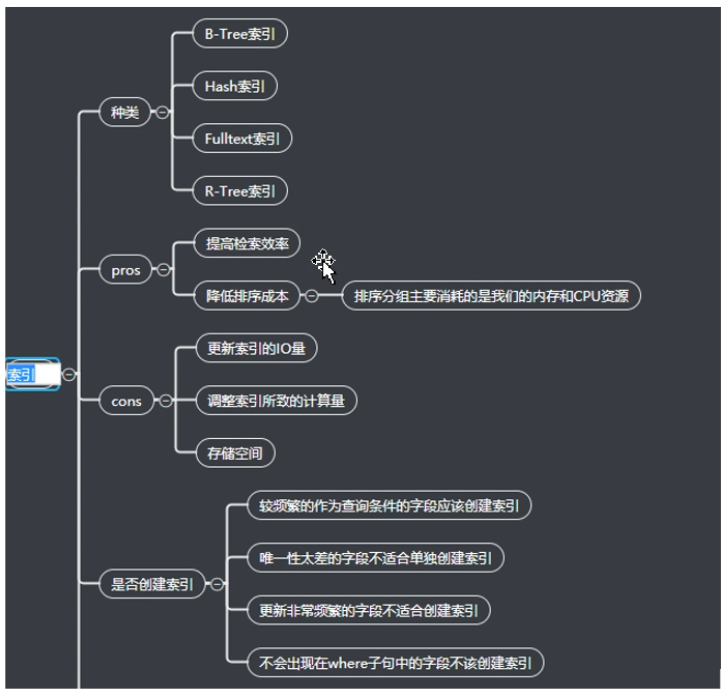
索引
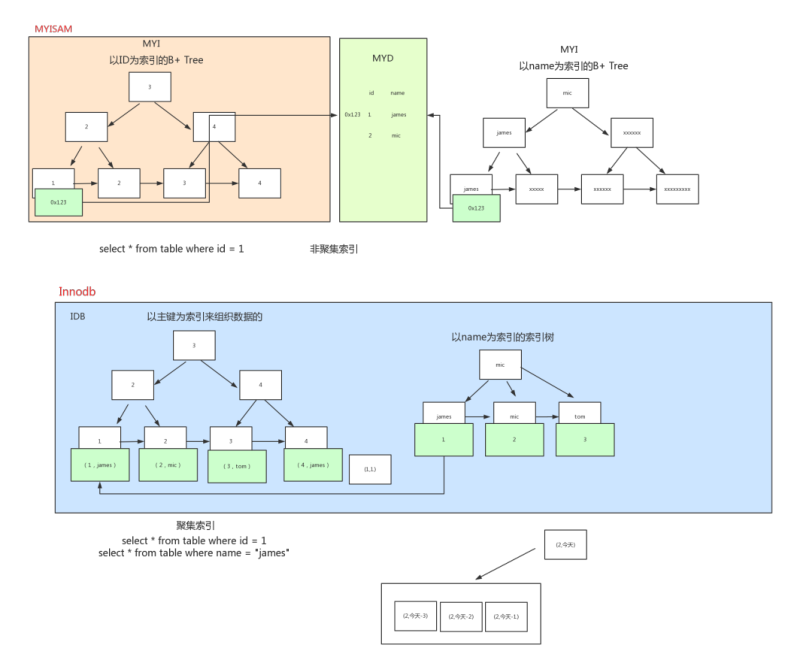
为什么主键是递增整数,而不使用UUID
- B树随机插入带来的性能消耗,而递增整形因为递增所以一直都会是操作B树的尾部
- UUID数据不具有物理连续性、且会导致空间碎片,不利于查询
- UUID存储占用相对于整形,占用增加
回表
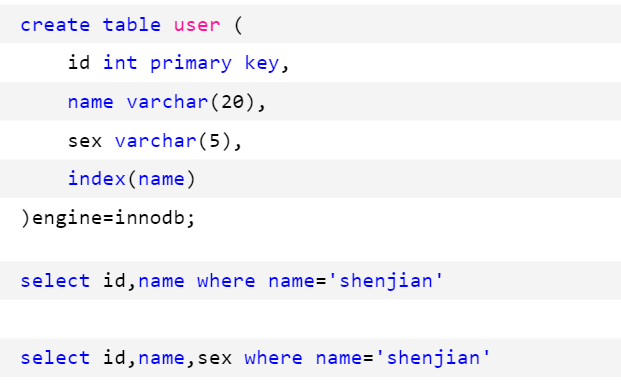
多查询了一个属性,为何检索过程完全不同?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
- 聚集索引(clustered index)
- 普通索引(secondary index)
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
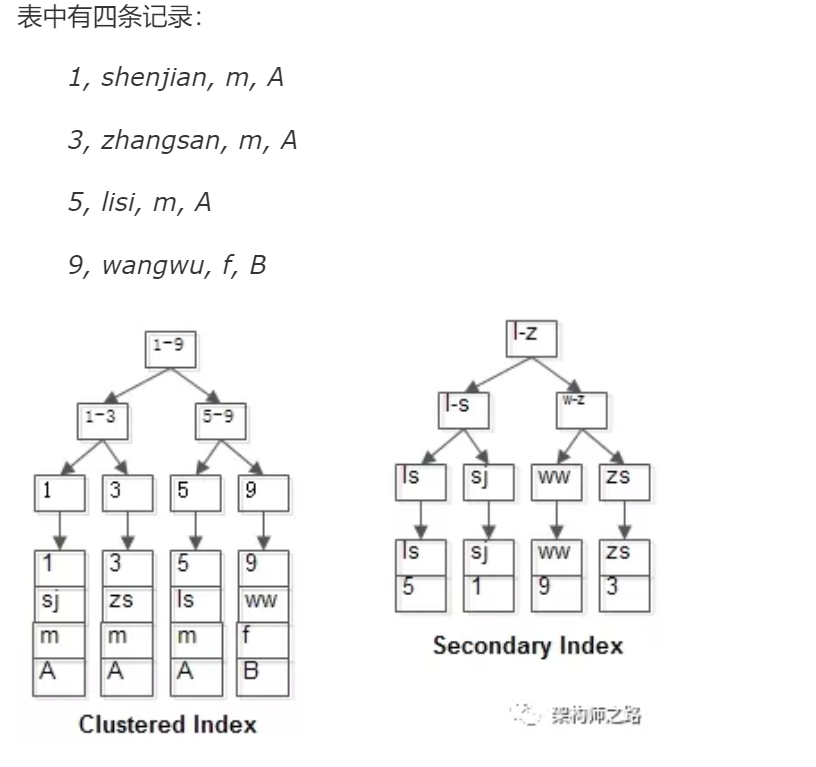
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
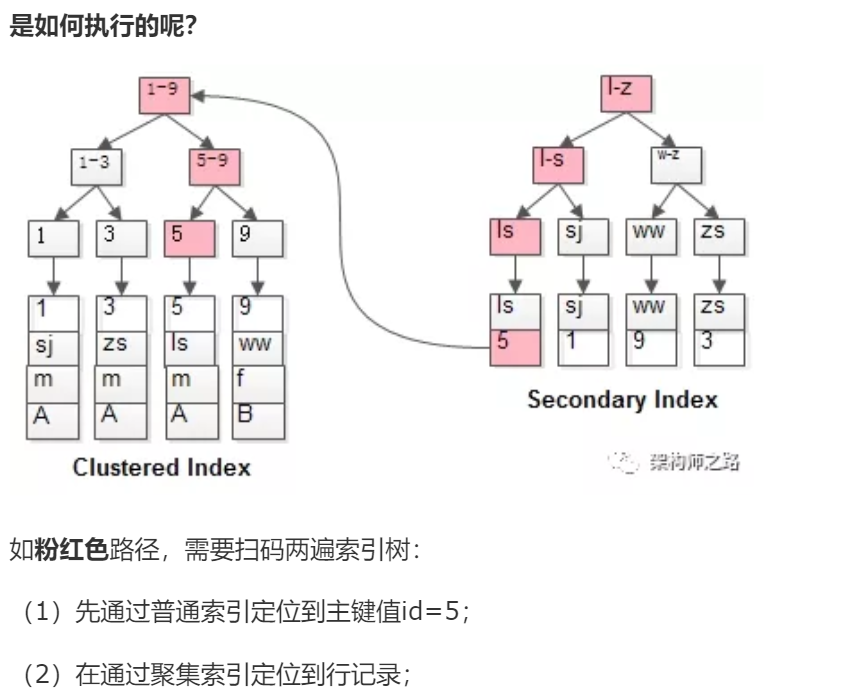
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
索引覆盖

第一个SQL语句:
第二个SQL语句:


哪些场景可以利用索引覆盖来优化SQL?
全表count查询优化

列查询回表优化

分页查询

锁
行锁
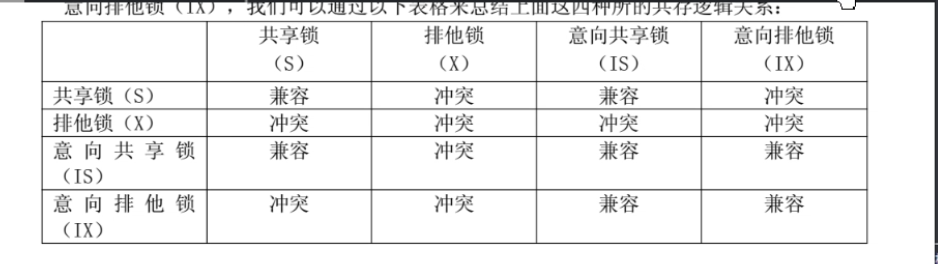
where条件(或者 for update)
- 当where有索引条件时,触发的是行锁。
- 如果where没有索引条件时,则触发表锁
- 使用’<>’,'like’等操作时,索引会失效
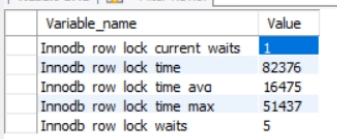
查看行级锁争用状态变量
1 | show status like 'innodb_row_lock%'; |
共享锁、读锁
1 | lock table tableName read; |
排它锁、血锁
1 | lock table tableName write; |
间隙锁
基于行锁的一个范围锁
页锁
表锁
查看表级锁的争用状态变量
1 | show status like 'table%'; |
优化
QEP (Query Execution Plan)



依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,
unique_subquery,index_subquery,range,index_merge,index,AL




总结
如果你看到以下现象,请优化:
- 出现了Using temporary;
- rows过多,或者几乎是全表的记录数;
- key 是 (NULL);
- possible_keys 出现过多(待选)索引。
Profiling
主要用来查看SQL执行的cpu、io的状况
1 | set profiling=1; |
join
1 | show variables like 'join_%'; |
底层实现
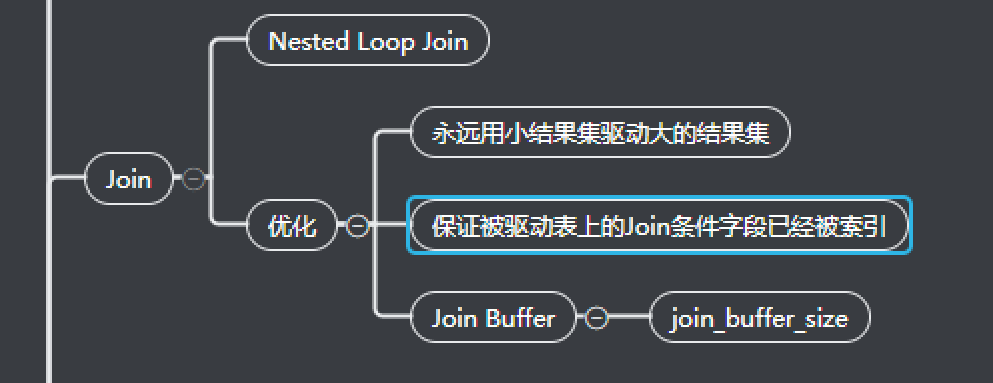
按照我们正常写代码的方式去理解就行,先查出驱动表的数据,单后通过驱动表中查到的数据,去join表中查找数据。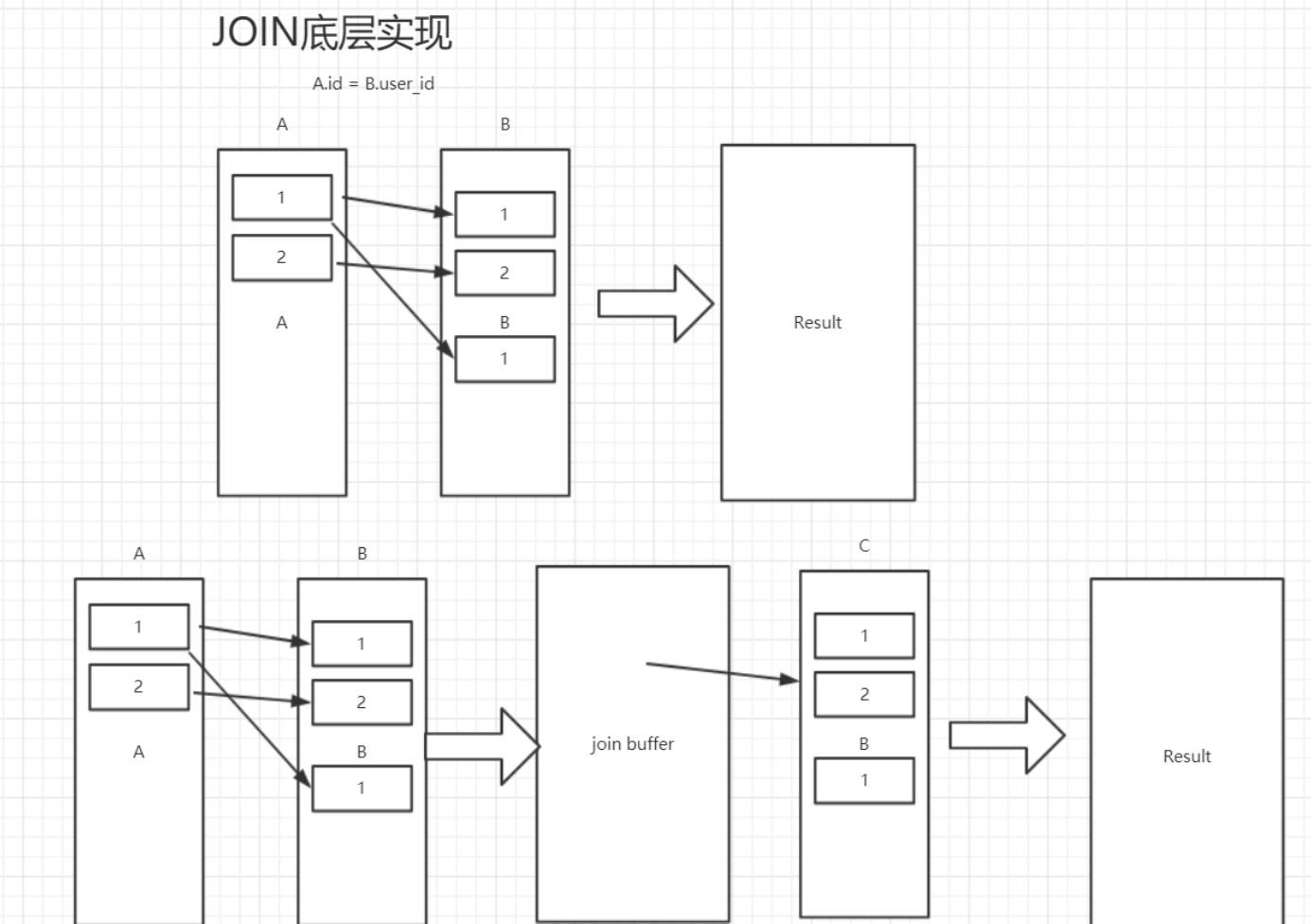
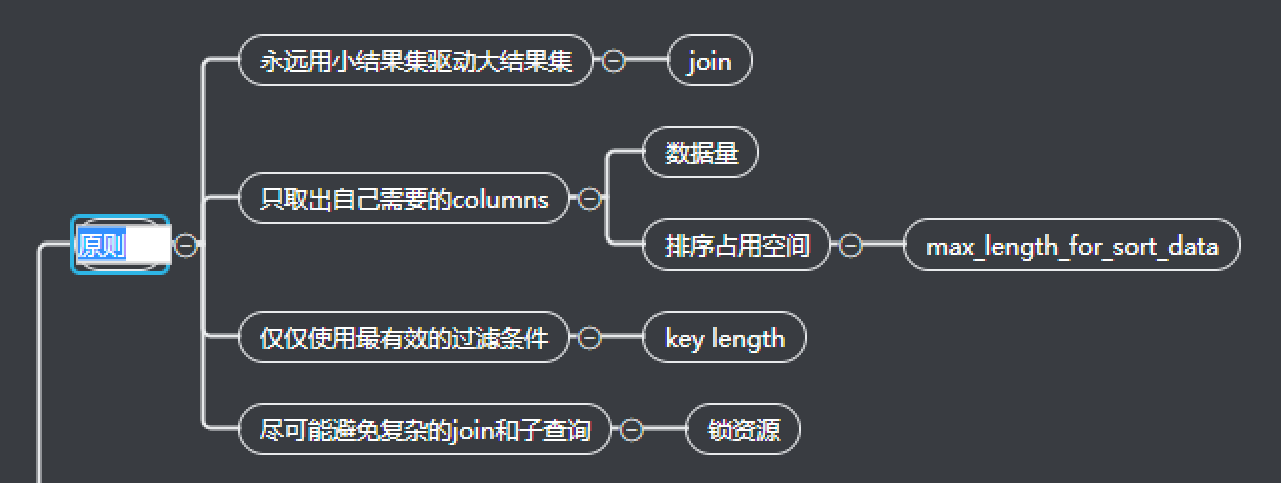
小结果集驱动大结果集,n*m 和 m*n
尽可能的减少对表数据的循环,个人理解,因为循环表数据,其实就是遍历聚集索引,就是遍历B+树,尽管很快,但是依旧需要寻址,查找等操作,索引尽可能的少去循环,索引要以小表作为驱动表。
join buffer
1 | show variables like 'join_%'; |
建议根据情况修改join buffer的大小,否则mysql会对缓存结果集进行分段处理,其中塞不下的部分放在磁盘上,那这个时候就会有磁盘IO消耗。
尽量不要根据非驱动表的字段排序
因为join也是遍历非驱动表的,如果对非驱动表中的字段进行排序,那么对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序!
去除所有JOIN,让MySQL自行决定
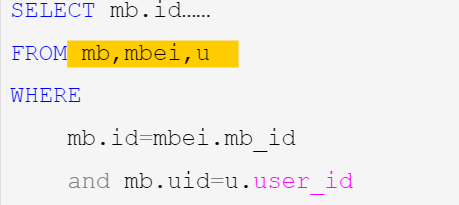
如果无法判断拿出表的大小,那就不要写join,因为mysql默认就是去查询表的大小,并且按照小表驱动大表的原则去查询。
order by
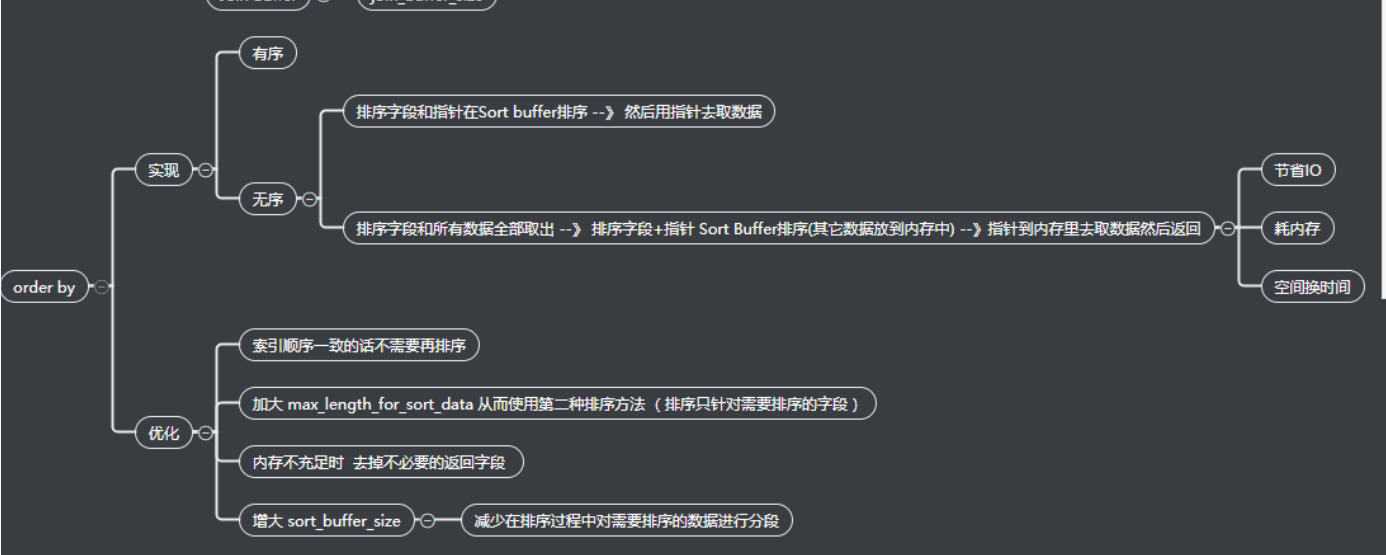
索引为什么可以排序?
以为B+树的叶子节点是相互指向的并且是排序的。
如果没有命中索引如何排序?
实现一:会把这列数据copy到缓存表中做排序,并且有个指针指向原来的数据,排序后就行指针回表查询,会有两次io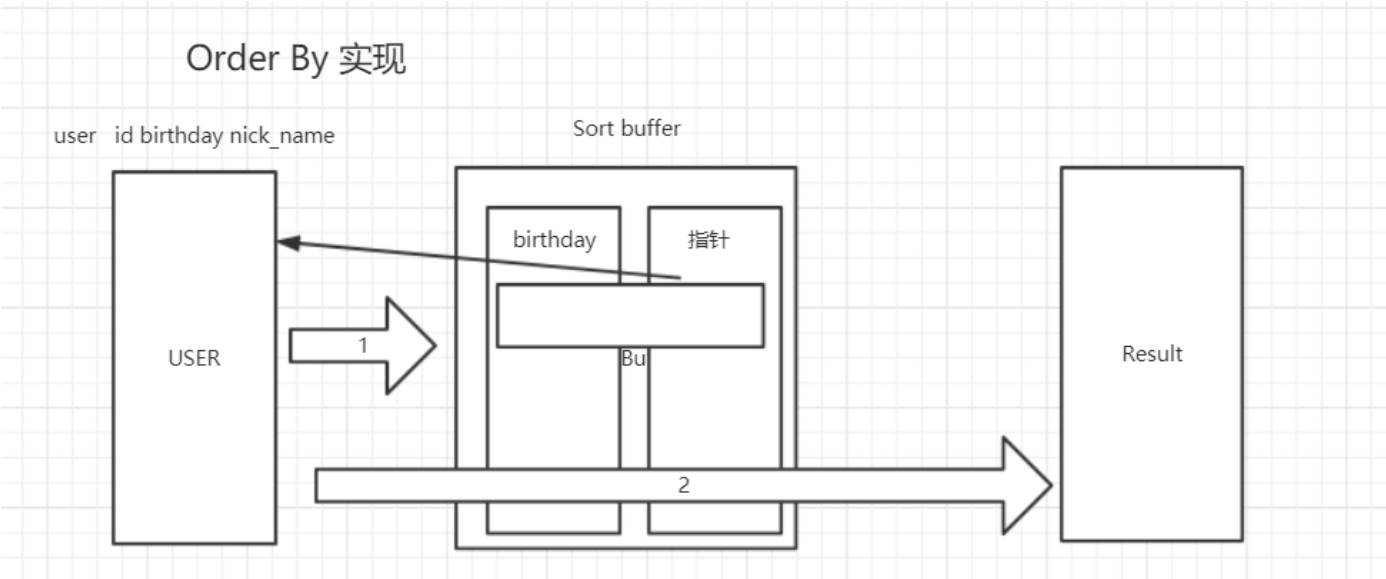
实现二:把需要查询出来的字段都copy到缓存表(a)中,并且把排序字段在拿到一个中间表(b)中,然后对相应的字段进行排序,同时还有个指针,指向表a中的地址,这样的只做了一次io,都是在内存中做的,空间换时间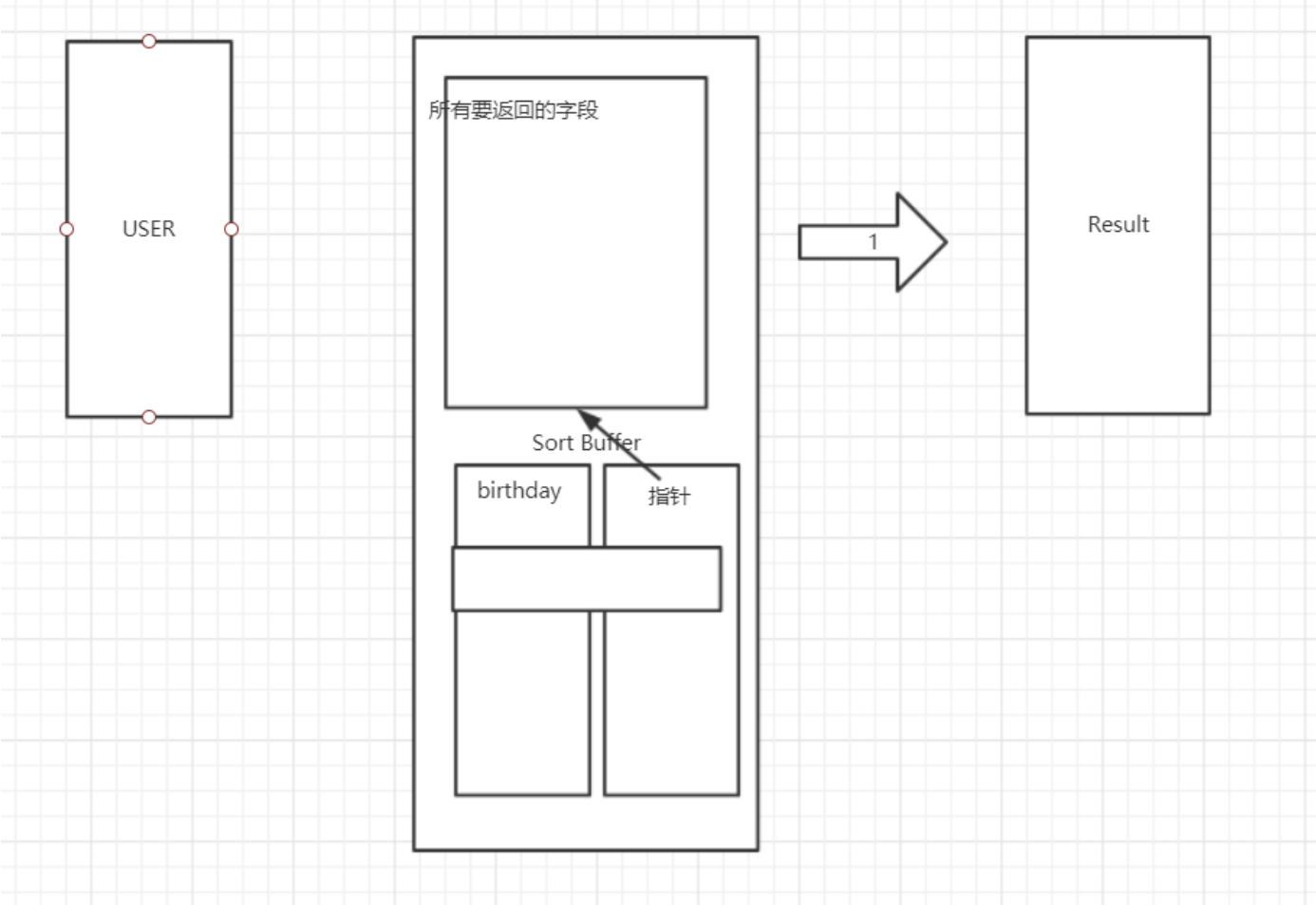
这两种方式是mysql自动选择的,当加大max_length_for_sort_data能放下中间表示就会使用实现二,否则使用实现一,select只查询出你需要的字段,这个也是原因之一。
这里和join buffer一样,可以根据情况,对sort buffer大小进行调整。
1 | show variables like '%sort%' |

排序字段尽量覆盖索引
索引字段默认就是排序的,所以查询的时候不在需要中间表去做排序
加大max_length_for_sort_data,尽量使用空间换时间
详情见 没有命中索引如何排序? 段落说明
内存不足时,去掉不必要的字段,不要使用*
- 详情见 没有命中索引如何排序? 段落说明
- 不需要字段的查询会査勇内存,网络,要避免
增加sort buffer,减少对排序数据的分段
分段的会吧多余数据存磁盘,又会造成io消耗,所以根据情况调大,尽可能避免这样的问题
group by
group by的前提排序
为什么的?
仔细想一想,他是怎么做到分组的,先排序,相同的字段一定会在一起,然后遍历,就能够分组了。
如果不先排序,那要怎么做呢,全部遍历,然后有个类似map这样的中间表进行存储,这种方式不就是无索引排序的范式么?
综上,group by的前提是排序,就是在排序的基础上做的
所以order by 的优化也适用group by优化。
Distinct
Distinct 去重字段,这个又是基于group by。
想一下,group by是分组,那么这个时候去重就很好做了。
所以,order by的优化也适用于distinct
limit
为什么limit 后数据大的话,为什么会慢的?
1 | SELECT * FROM user limit 10000,10; |
因为他会从0开始遍历,一直到10000.
使用> 或者 between
- SELECT * FROM user where id>10000 limit 10;
- 如果不是基于主键索引的,使用的是普通索引的,那么就要使用索引覆盖:select id from user where name=‘xxx’ limit 10000, 10 依据普通索引的特性,先查出id,然后通过id在去查询数据。
总结
任何数据库层面的优化都抵不上应用系统的优化!!!
slow sql 配置

性能优化概念