Netty
概念
通过使用 Netty(NIO 框架)相比于传统基于 Java 序列化+BIO(同步阻塞 IO)的通信框架, 性能差不多提升了 8 倍多。
Netty 是一个高性能、异步事件驱动的 NIO 框架,它提供了对 TCP、UDP 和文件传输的支持,
作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞的,通过 Future-Listener 机制,
用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。 作为当前最流行的 NIO 框架,Netty 在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,
一些业界著名的开源组件也基于 Netty 的 NIO 框架构建。
高性能
RPC 调用的性能模型分析
传统 RPC 调用性能差的原因
网络传输方式问题:传统的 RPC 框架或者基于 RMI 等方式的远程服务(过程)调用采用了同 步阻塞 IO,
当客户端的并发压力或者网络时延增大之后,同步阻塞 IO 会由于频繁的 wait 导致 IO 线程经常性的阻塞,由于线程无法高效的工作,IO 处理能力自然下降。、
下面,我们通过 BIO 通信模型图看下 BIO 通信的弊端: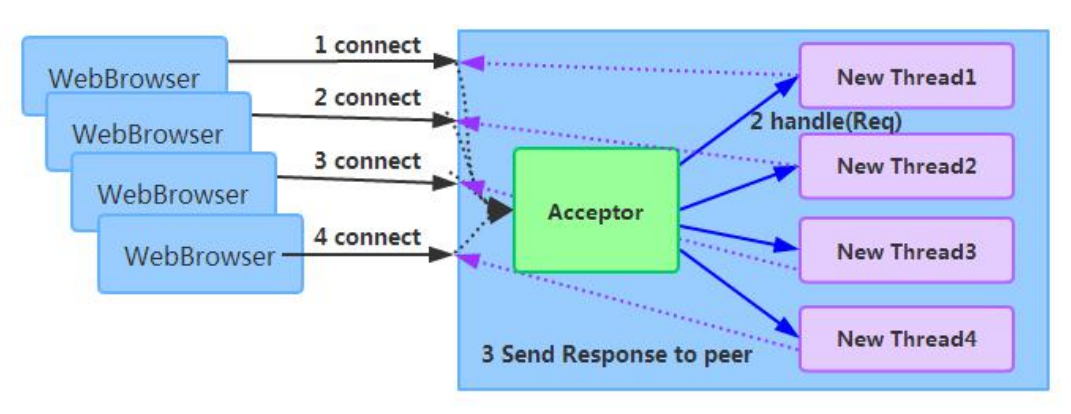
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接,接
收到客户端连接之后为客户端连接创建一个新的线程处理请求消息,处理完成之后,返回应
答消息给客户端,线程销毁,这就是典型的一请求一应答模型。该架构最大的问题就是不具
备弹性伸缩能力,当并发访问量增加后,服务端的线程个数和并发访问数成线性正比,由于
线程是 JAVA 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能急剧下降,随着
并发量的继续增加,可能会发生句柄溢出、线程堆栈溢出等问题,并导致服务器最终宕机。
序列化方式问题:Java 序列化存在如下几个典型问题:
- Java 序列化机制是 Java 内部的一种对象编解码技术,无法跨语言使用;例如对于异构系统之间的对接,Java 序列化后的码流需要能够通过其它语言反序列化成原始对象(副本),目前很难支持;
- 相比于其它开源的序列化框架,Java 序列化后的码流太大,无论是网络传输还是持久化到磁盘,都会导致额外的资源占用;
- 序列化性能差(CPU 资源占用高)。
线程模型问题:由于采用同步阻塞 IO,这会导致每个 TCP 连接都占用 1 个线程,由于线程
资源是 JVM 虚拟机非常宝贵的资源,当 IO 读写阻塞导致线程无法及时释放时,会导致系统
性能急剧下降,严重的甚至会导致虚拟机无法创建新的线程。
高性能的三个方面
- 传输:用什么样的通道将数据发送给对方,BIO、NIO 或者 AIO,IO 模型在很大程度上决定了框架的性能。
- 协议:采用什么样的通信协议,HTTP 或者内部私有协议。协议的选择不同,性能模型也不同。相比于公有协议,内部私有协议的性能通常可以被设计的更优。
- 线程:数据报如何读取?读取之后的编解码在哪个线程进行,编解码后的消息如何派发,Reactor 线程模型的不同,对性能的影响也非常大。
Netty高性能
异步非阻塞通信
在 IO 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者 IO 多路复
用技术进行处理。IO 多路复用技术通过把多个 IO 的阻塞复用到同一个 select 的阻塞上,
从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模
型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也
不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。
JDK1.4 提供了对非阻塞 IO(NIO)的支持,JDK1.5_update10 版本使用 epoll 替代了传统的
select/poll,极大的提升了 NIO 通信的性能。
JDK NIO 通信模型如下所示: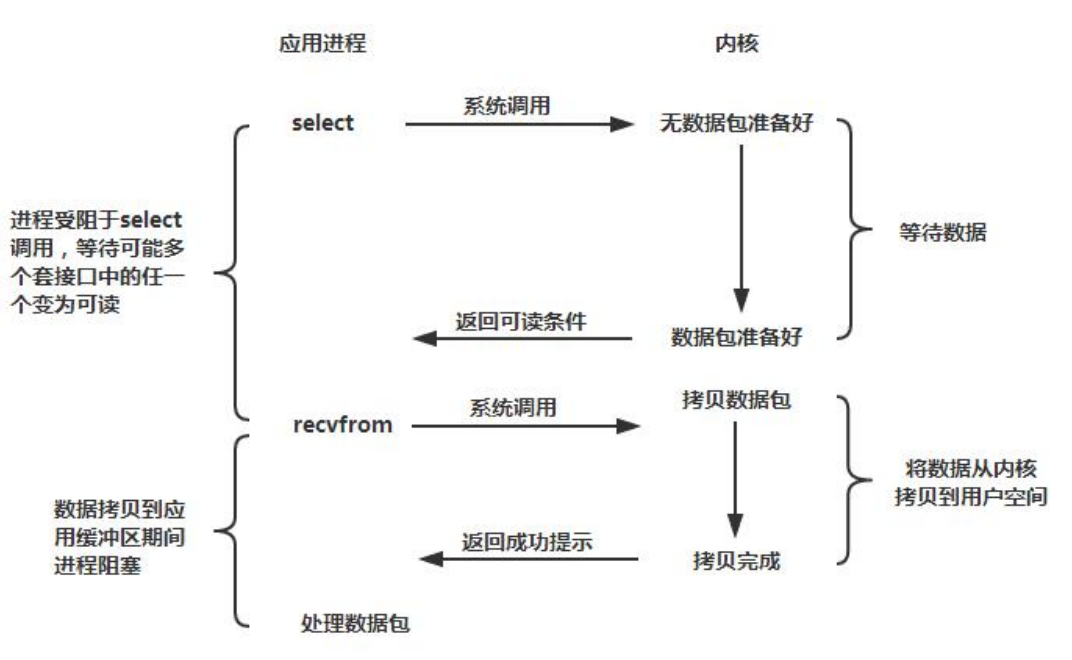
与 Socket 类和 ServerSocket 类相对应,NIO 也提供了 SocketChannel 和
ServerSocketChannel 两种不同的套接字通道实现。这两种新增的通道都支持阻塞和非阻塞
两种模式。阻塞模式使用非常简单,但是性能和可靠性都不好,非阻塞模式正好相反。开发
人员一般可以根据自己的需要来选择合适的模式,一般来说,低负载、低并发的应用程序可
以选择同步阻塞 IO 以降低编程复杂度。但是对于高负载、高并发的网络应用,需要使用 NIO的非阻塞模式进行开发。
Netty 架构按照 Reactor 模式设计和实现,它的服务端通信序列图如下: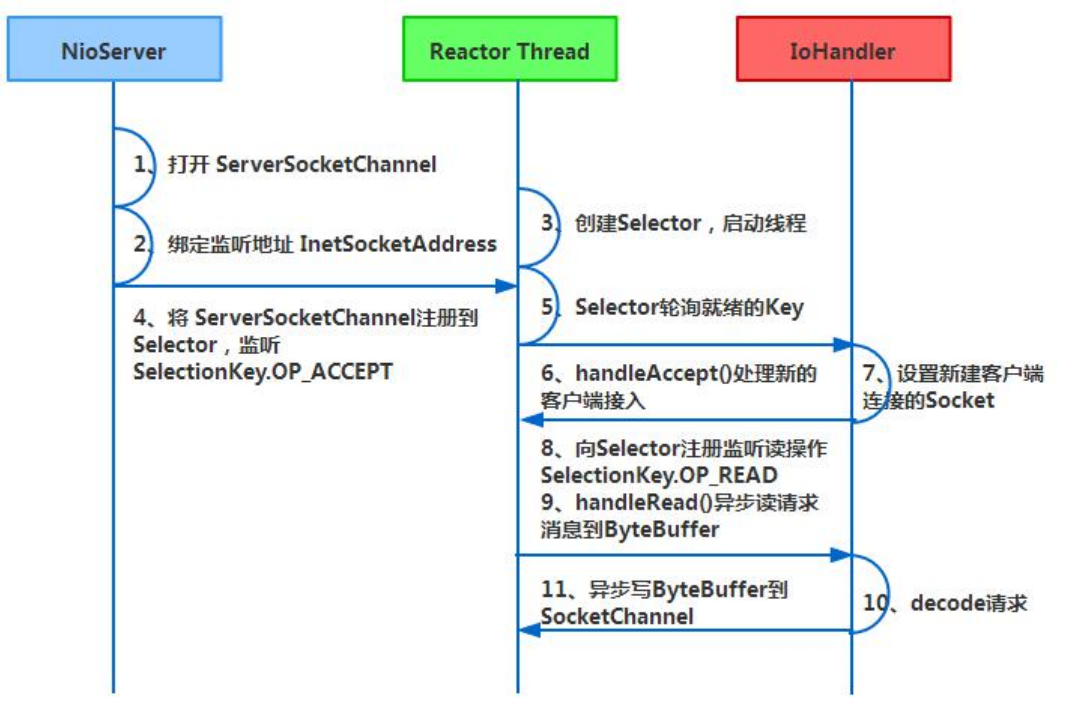
客户端通信序列图如下: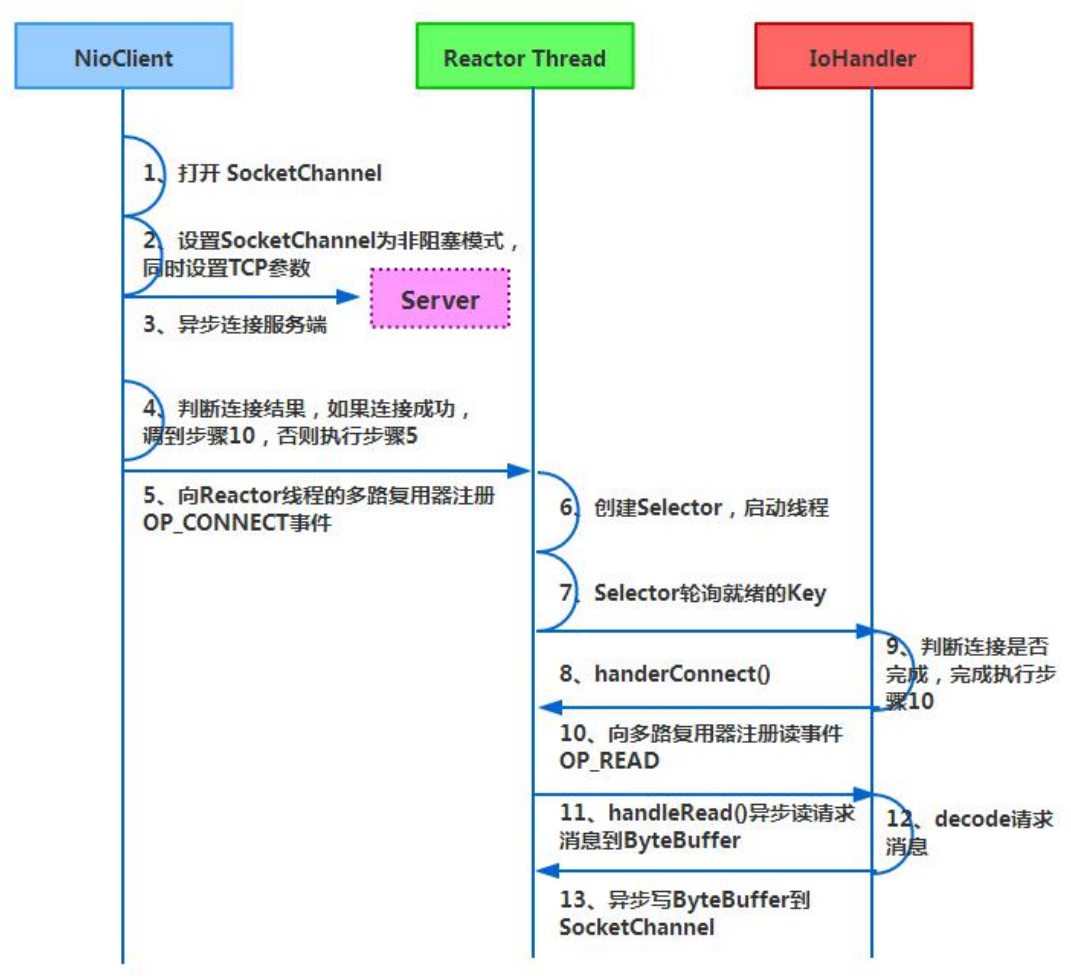
Netty 的 IO 线程 NioEventLoop 由于聚合了多路复用器 Selector,可以同时并发处理成百上
千个客户端 Channel,由于读写操作都是非阻塞的,这就可以充分提升 IO 线程的运行效率,
避免由于频繁 IO 阻塞导致的线程挂起。另外,由于 Netty 采用了异步通信模式,一个 IO
线程可以并发处理 N 个客户端连接和读写操作,这从根本上解决了传统同步阻塞 IO 一连接
一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
零拷贝
很多用户都听说过 Netty 具有“零拷贝”功能,但是具体体现在哪里又说不清楚,本小节就详细对 Netty 的“零拷贝”功能进行讲解。
Netty 的“零拷贝”主要体现在如下三个方面:
- Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty 提供了组合 Buffer 对象,可以聚合多个 ByteBuffer 对象,用户可以像操作一个Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小Buffer 合并成一个大的 Buffer。
- Netty 的文件传输采用了 transferTo 方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环 write 方式导致的内存拷贝问题。
下面,我们对上述三种“零拷贝”进行说明,先看 Netty 接收 Buffer 的创建:
AbstractNioByteChannel
打开 AbstractNioByteChannel$NioByteUnsafe
1 | protected class NioByteUnsafe extends AbstractNioUnsafe { |
再找到 do while 中的 allocHandle.allocate(allocator) 方法,实际上调用的是
DefaultMaxMessageRecvByteBufAllocator$MaxMessageHandle 的 allocate 方法
1 | public ByteBuf allocate(ByteBufAllocator alloc) { |
当进行 Socket IO 读写的时候,为了避免从堆内存拷贝一份副本到直接内存,Netty 的
ByteBuf 分配器直接创建非堆内存避免缓冲区的二次拷贝,通过“零拷贝”来提升读写性能。
CompositeByteBuf
下面我们继续看第二种“零拷贝”的实现 CompositeByteBuf,它对外将多个 ByteBuf 封装
成一个 ByteBuf,对外提供统一封装后的 ByteBuf 接口,
CompositeByteBuf 实际就是个 ByteBuf 的包装器,它将多个
ByteBuf 组合成一个集合,然后对外提供统一的 ByteBuf 接口,相关定义如下:
1 | public class CompositeByteBuf extends AbstractReferenceCountedByteBuf implements Iterable<ByteBuf> { |
添加 ByteBuf,不需要做内存拷贝,相关代码如下
1 | private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) { |
文件传输的“零拷贝“
Netty 文件传输 DefaultFileRegion 通过 transferTo 方法将文件发送到目标 Channel 中,
下面重点看 FileChannel 的 transferTo 方法,它的 API DOC 说明如下:
1 | public long transferTo(WritableByteChannel target, long position) throws IOException { |
对于很多操作系统它直接将文件缓冲区的内容发送到目标 Channel 中,而不需要通过拷贝的
方式,这是一种更加高效的传输方式,它实现了文件传输的“零拷贝”。
内存池
随着 JVM 虚拟机和 JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但
是对于缓冲区 Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件
耗时的操作。为了尽量重用缓冲区,Netty 提供了基于内存池的缓冲区重用机制。下面我们
一起看下 Netty ByteBuf 的实现: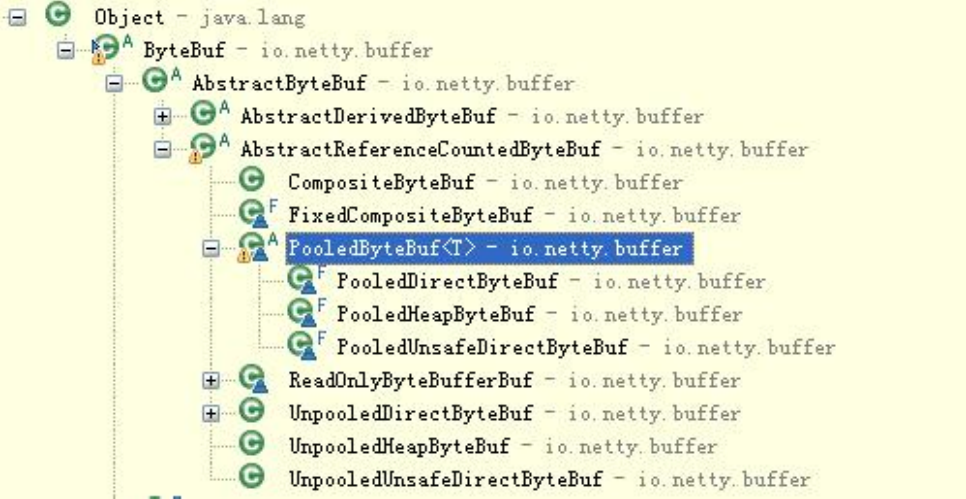
Netty 提供了多种内存管理策略,通过在启动辅助类中配置相关参数,可以实现差异化的定
制。
下面我们一起简单分析下 Netty 内存池的内存分配,
Unpooled.directBuffer(1024);
1 |
|
继续看 newDirectBuffer 方法,我们发现它是一个抽象方法,由 AbstractByteBufAllocator
的子类负责具体实现
代码跳转到 PooledByteBufAllocator 的 newDirectBuffer 方法,从 Cache 中获取内存区域
PoolArena,调用它的 allocate 方法进行内存分配:
1 | private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { |
PoolArena 的 allocate 方法如下:
1 | PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) { |
我们重点分析 newByteBuf 的实现,它同样是个抽象方法,由子类 DirectArena 和 HeapArena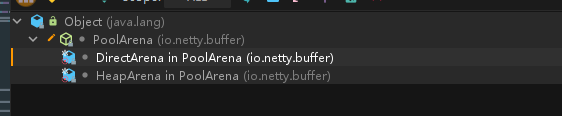
分析 DirectArena 的实现:如果没有开启使用 sun 的 unsafe,则
1 |
|
执行 PooledDirectByteBuf 的 newInstance 方法,代码如下:
1 | static PooledDirectByteBuf newInstance(int maxCapacity) { |
通过 RECYCLER 的 get 方法循环使用 ByteBuf 对象,如果是非内存池实现,则直接创建一个
新的 ByteBuf 对象。从缓冲池中获取 ByteBuf 之后,调用 AbstractReferenceCountedByteBuf
的 setRefCnt 方法设置引用计数器,用于对象的引用计数和内存回收(类似 JVM 垃圾回收机
制)。
高效的 Reactor 线程模型
常用的 Reactor 线程模型有三种,分别如下:
- Reactor 单线程模型;
- Reactor 多线程模型;
- 主从 Reactor 多线程模型
Reactor 单线程模型,指的是所有的 IO 操作都在同一个 NIO 线程上面完成,NIO 线程的职责,如下:
- 作为 NIO 服务端,接收客户端的 TCP 连接;
- 作为 NIO 客户端,向服务端发起 TCP 连接;
- 读取通信对端的请求或者应答消息;
- 向通信对端发送消息请求或者应答消息。
Reactor 单线程模型示意图如下所示: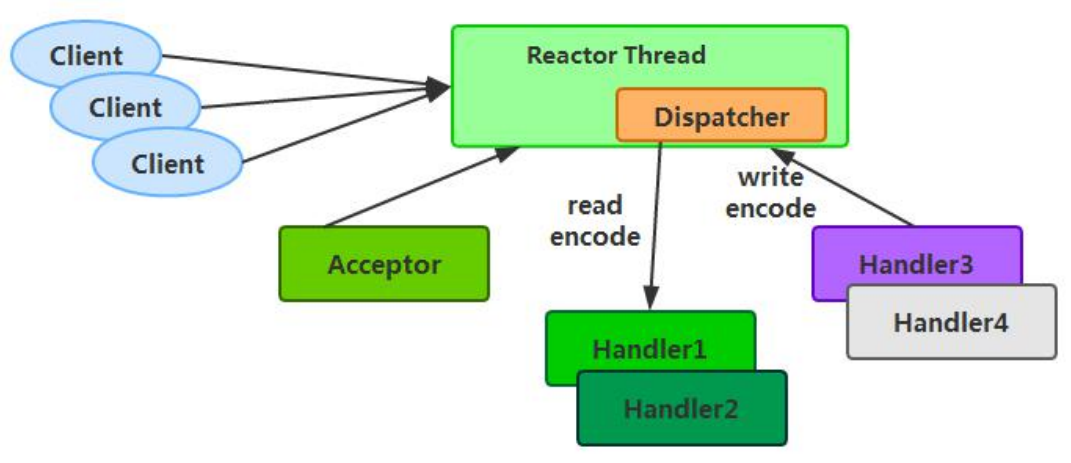
由于 Reactor 模式使用的是异步非阻塞 IO,所有的 IO 操作都不会导致阻塞,理论上一个线
程可以独立处理所有 IO 相关的操作。从架构层面看,一个 NIO 线程确实可以完成其承担的
职责。例如,通过 Acceptor 接收客户端的 TCP 连接请求消息,链路建立成功之后,通过
Dispatch 将对应的 ByteBuffer 派发到指定的 Handler 上进行消息解码。用户 Handler 可以
通过 NIO 线程将消息发送给客户端。
对于一些小容量应用场景,可以使用单线程模型。但是对于高负载、大并发的应用却不合适,
主要原因如下:
- 一个 NIO 线程同时处理成百上千的链路,性能上无法支撑,即便 NIO 线程的 CPU 负荷达到 100%,也无法满足海量消息的编码、解码、读取和发送;
- 当 NIO 线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了 NIO 线程的负载,最终会导致大量消息积压和处理超时,NIO线程会成为系统的性能瓶颈;
- 可靠性问题:一旦 NIO 线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
为了解决这些问题,演进出了 Reactor 多线程模型,下面我们一起学习下 Reactor 多线程模型。
Rector 多线程模型与单线程模型最大的区别就是有一组 NIO 线程处理 IO 操作,它的原理图
如下: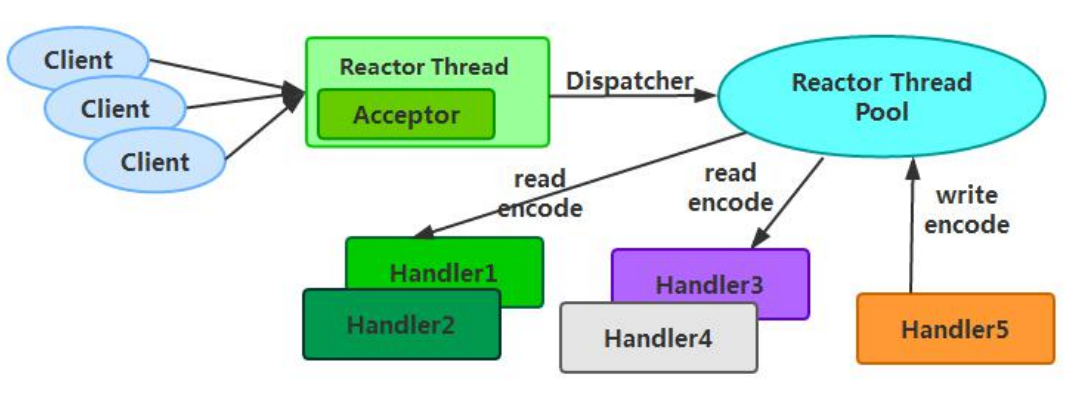
Reactor 多线程模型的特点:
- 有专门一个 NIO 线程-Acceptor 线程用于监听服务端,接收客户端的 TCP 连接请求;
- 网络 IO 操作-读、写等由一个 NIO 线程池负责,线程池可以采用标准的 JDK 线程池实现,它包含一个任务队列和 N 个可用的线程,由这些 NIO 线程负责消息的读取、解码、编码和发送;
- 1 个 NIO 线程可以同时处理 N 条链路,但是 1 个链路只对应 1 个 NIO 线程,防止发生并发操作问题。
在绝大多数场景下,Reactor 多线程模型都可以满足性能需求;但是,在极特殊应用场景中,
一个 NIO 线程负责监听和处理所有的客户端连接可能会存在性能问题。例如百万客户端并发
连接,或者服务端需要对客户端的握手消息进行安全认证,认证本身非常损耗性能。在这类
场景下,单独一个 Acceptor 线程可能会存在性能不足问题,为了解决性能问题,产生了第
三种 Reactor 线程模型-主从 Reactor 多线程模型。
主从 Reactor 线程模型的特点是:服务端用于接收客户端连接的不再是个 1 个单独的 NIO
线程,而是一个独立的 NIO 线程池。Acceptor 接收到客户端 TCP 连接请求处理完成后(可
能包含接入认证等),将新创建的 SocketChannel 注册到 IO 线程池(sub reactor 线程池)
的某个 IO 线程上,由它负责 SocketChannel 的读写和编解码工作。Acceptor 线程池仅仅只
用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端 subReactor
线程池的 IO 线程上,由 IO 线程负责后续的 IO 操作。
它的线程模型如下图所示: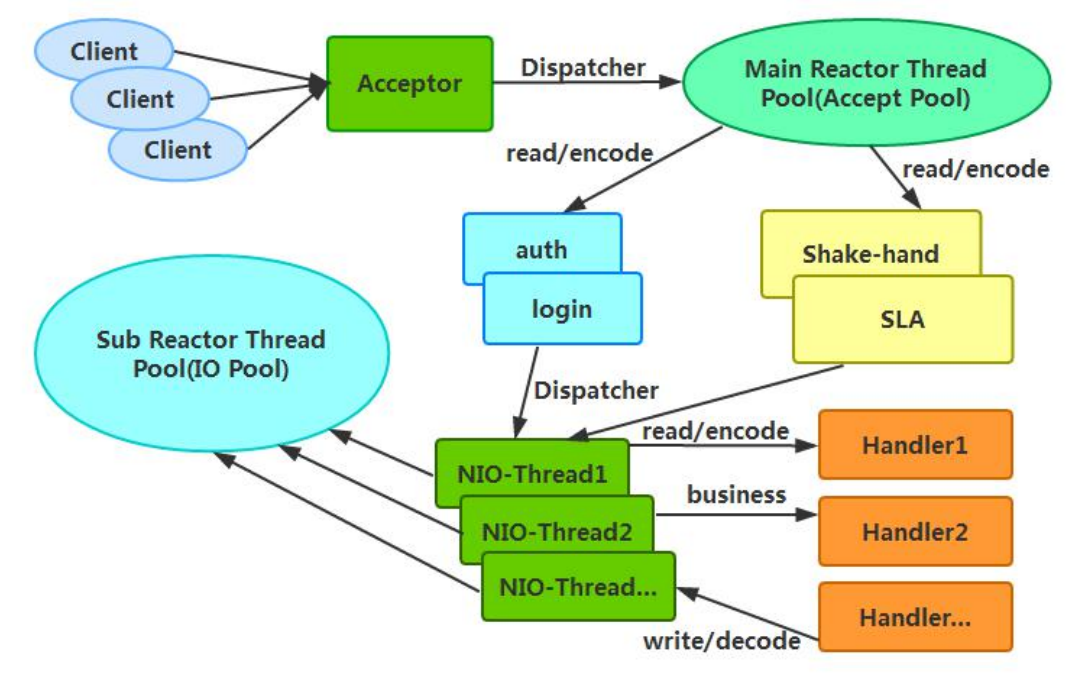
利用主从 NIO 线程模型,可以解决 1 个服务端监听线程无法有效处理所有客户端连接的性能
不足问题。因此,在 Netty 的官方 demo 中,推荐使用该线程模型。
事实上,Netty 的线程模型并非固定不变,通过在启动辅助类中创建不同的 EventLoopGroup
实例并通过适当的参数配置,就可以支持上述三种 Reactor 线程模型。正是因为 Netty 对
Reactor 线程模型的支持提供了灵活的定制能力,所以可以满足不同业务场景的性能诉求。
无锁化的串行设计理念
在大多数场景下,并行多线程处理可以提升系统的并发性能。但是,如果对于共享资源的并
发访问处理不当,会带来严重的锁竞争,这最终会导致性能的下降。为了尽可能的避免锁竞
争带来的性能损耗,可以通过串行化设计,即消息的处理尽可能在同一个线程内完成,期间
不进行线程切换,这样就避免了多线程竞争和同步锁。
为了尽可能提升性能,Netty 采用了串行无锁化设计,在 IO 线程内部进行串行操作,避免
多线程竞争导致的性能下降。表面上看,串行化设计似乎 CPU 利用率不高,并发程度不够。
但是,通过调整 NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局
部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。
Netty 的串行化设计工作原理图如下:
Netty 的 NioEventLoop 读取到消息之后,直接调用 ChannelPipeline 的
fireChannelRead(Object msg),只要用户不主动切换线程,一直会由 NioEventLoop 调用到
用户的 Handler,期间不进行线程切换,这种串行化处理方式避免了多线程操作导致的锁的
竞争,从性能角度看是最优的。
高效的并发编程
Netty 的高效并发编程主要体现在如下几点:
- volatile 的大量、正确使用;
- CAS 和原子类的广泛使用;
- 线程安全容器的使用;
- 通过读写锁提升并发性能。
高性能的序列化框架
影响序列化性能的关键因素总结如下:
- 序列化后的码流大小(网络带宽的占用)
- 序列化&反序列化的性能(CPU 资源占用)
- 是否支持跨语言(异构系统的对接和开发语言切换)
Netty 默认提供了对 Google Protobuf 的支持,通过扩展 Netty 的编解码接口,用户可以实
现其它的高性能序列化框架,例如 Thrift 的压缩二进制编解码框架。
下面我们一起看下不同序列化&反序列化框架序列化后的字节数组对比: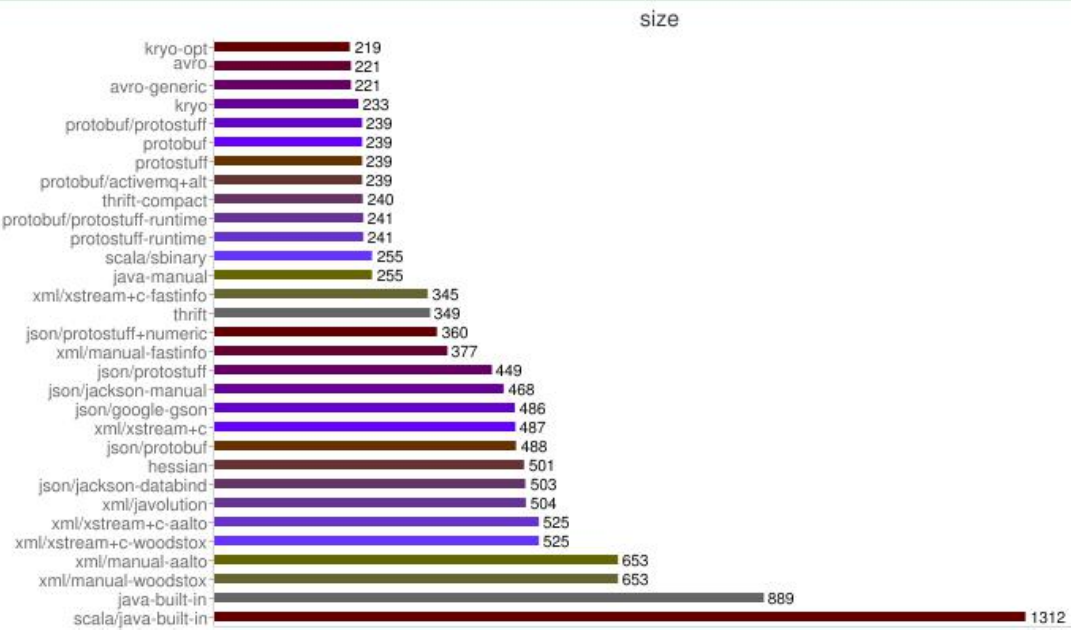
从上图可以看出,Protobuf 序列化后的码流只有 Java 序列化的 1/4 左右。正是由于 Java
原生序列化性能表现太差,才催生出了各种高性能的开源序列化技术和框架(性能差只是其
中的一个原因,还有跨语言、IDL 定义等其它因素)。
灵活的 TCP 参数配置能力
合理设置 TCP 参数在某些场景下对于性能的提升可以起到显著的效果,例如 SO_RCVBUF 和
SO_SNDBUF。如果设置不当,对性能的影响是非常大的。下面我们总结下对性能影响比较大
的几个配置项:
- SO_RCVBUF 和 SO_SNDBUF:通常建议值为 128K 或者 256K;
- SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法;
- 软中断:如果 Linux 内核版本支持 RPS(2.6.35 以上版本),开启 RPS 后可以实现软中断,提升网络吞吐量。RPS 根据数据包的源地址,目的地址以及目的和源端口,计算出一个hash 值,然后根据这个 hash 值来选择软中断运行的 cpu,从上层来看,也就是说将每个连接和 cpu 绑定,并通过这个 hash 值,来均衡软中断在多个 cpu 上,提升网络并行处理性能。
Netty 在启动辅助类中可以灵活的配置 TCP 参数,满足不同的用户场景。相关配置接口定义
如下:
总结
通过对 Netty 的架构和性能模型进行分析,我们发现 Netty 架构的高性能是被精心设计和实
现的,得益于高质量的架构和代码,Netty 支持 10W TPS 的跨节点服务调用并不是件十分困
难的事情。
源码
BootStrap
客户端 BootStrap
Bootstrap 是 Netty 提供的一个便利的工厂类, 我们可以通过它来完成 Netty 的客户端或服
务器端的 Netty 初始化.
下面我先来看一个例子, 从客户端和服务器端分别分析一下 Netty 的程序是如何启动的。
首先,让我们从客户端方面的代码开始
1 | public class ChatClient { |
从上面的客户端代码虽然简单, 但是却展示了 Netty 客户端初始化时所需的所有内容:
- EventLoopGroup: 不论是服务器端还是客户端, 都必须指定 EventLoopGroup. 在这个例子中, 指定了 NioEventLoopGroup, 表示一个 NIO 的 EventLoopGroup.
- ChannelType: 指定 Channel 的类型. 因为是客户端, 因此使用了 NioSocketChannel.
- Handler: 设置数据的处理器.
NioSocketChannel 的初始化过程
在 Netty 中, Channel 是一个 Socket 的抽象, 它为用户提供了关于 Socket 状态(是否是连接还是断开) 以及对 Socket 的读写等操作. 每当 Netty 建立了一个连接后, 都会有一个对应的 Channel 实例.
NioSocketChannel 的类层次结构如下: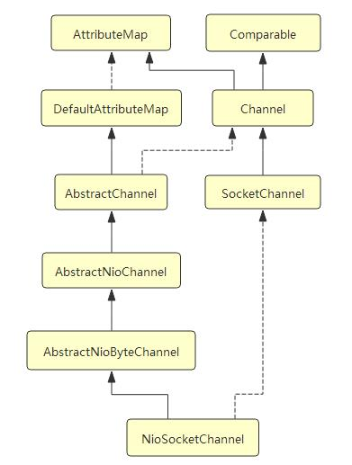
接下来我们着重分析一下 Channel 的初始化过程。
ChannelFactory 和 Channel 类型的确定
除了 TCP 协议以外, Netty 还支持很多其他的连接协议, 并且每种协议还有 NIO(非阻塞 IO)
和 OIO(Old-IO, 即传统的阻塞 IO) 版本的区别. 不同协议不同的阻塞类型的连接都有不同的
Channel 类型与之对应下面是一些常用的 Channel 类型:
- oSocketChannel, 代表异步的客户端 TCP Socket 连接.
- NioServerSocketChannel, 异步的服务器端 TCP Socket 连接.
- NioDatagramChannel, 异步的 UDP 连接
- NioSctpChannel, 异步的客户端 Sctp 连接.
- NioSctpServerChannel, 异步的 Sctp 服务器端连接.
- OioSocketChannel, 同步的客户端 TCP Socket 连接.
- OioServerSocketChannel, 同步的服务器端 TCP Socket 连接.
- OioDatagramChannel, 同步的 UDP 连接
- OioSctpChannel, 同步的 Sctp 服务器端连接.
- OioSctpServerChannel, 同步的客户端 TCP Socket 连接.
那么我们是如何设置所需要的 Channel 的类型的呢? 答案是 channel() 方法的调用.
在客户端连接代码的初始化 Bootstrap 中, 会调用 channel() 方法, 传入NioSocketChannel.class, 这个方法其实就是初始化了一个 ReflectiveChannelFactory:
1 | public B channel(Class<? extends C> channelClass) { |
而 ReflectiveChannelFactory 实现了 ChannelFactory 接口, 它提供了唯一的方法, 即
newChannel. ChannelFactory, 顾名思义, 就是产生 Channel 的工厂类.
进入到 ReflectiveChannelFactory.newChannel 中, 我们看到其实现代码如下:
1 |
|
根据上面代码的提示, 我们就可以确定:
- Bootstrap 中的 ChannelFactory 的实现是 ReflectiveChannelFactory
- 生成的 Channel 的具体类型是 NioSocketChannel.
Channel 的实例化过程, 其实就是调用的 ChannelFactory.newChannel 方法, 而实例化的
Channel 的具体的类型又是和在初始化 Bootstrap 时传入的 channel() 方法的参数相关. 因此对于 我们这个 例子中的客 户端的 Bootstrap 而言 , 生成的 的 Channel 实例就 是NioSocketChannel.
Channel的实例化
前面我们已经知道了如何确定一个 Channel 的类型, 并且了解到 Channel 是通过工厂方法
ChannelFactory.newChannel() 来实例化的, 那么 ChannelFactory.newChannel() 方法在哪里
调用呢?继续跟踪, 我们发现其调用链是:
Bootstrap.connect->Bootstrap.doResolveAndConnect->AbstractBootstrap.i
nitAndRegister
在AbstractBootstrap.initAndRegister中调用了channelFactory().newChannel()来获取一个
新的 NioSocketChannel 实例, 其源码如下:
1 | final ChannelFuture initAndRegister() { |
在 newChannel 中, 通过类对象的 newInstance 来获取一个新 Channel 实例, 因而会调用
NioSocketChannel 的默认构造器.NioSocketChannel 默认构造器代码如下:
1 | public NioSocketChannel() { |
这里的代码比较关键, 我们看到, 在这个构造器中, 会调用 newSocket 来打开一个新的 Java
NIO SocketChannel:
1 | private static SocketChannel newSocket(SelectorProvider provider) { |
接着会调用父类, 即 AbstractNioByteChannel 的构造器:
1 | AbstractNioByteChannel(Channel parent, SelectableChannel ch) |
并传入参数 parent 为 null, ch 为刚才使用 newSocket 创建的 Java NIO SocketChannel, 因
此生成的 NioSocketChannel 的 parent channel 是空的.
1 | protected AbstractNioByteChannel(Channel parent, SelectableChannel ch) { |
接着会继续调用父类 AbstractNioChannel 的构造器, 并传入了参数 readInterestOp =
SelectionKey.OP_READ:
1 | protected AbstractNioChannel(Channel parent, SelectableChannel ch, int readInterestOp) |
然后继续调用父类 AbstractChannel 的构造器:
1 | protected AbstractChannel(Channel parent) { |
到这里, 一个完整的 NioSocketChannel 就初始化完成了, 我们可以稍微总结一下构造一个NioSocketChannel 所需要做的工作:
- 调 用 NioSocketChannel.newSocket(DEFAULT_SELECTOR_PROVIDER) 打 开 一 个 新 的Java NIO SocketChannel
- AbstractChannel(Channel parent) 中初始化 AbstractChannel 的属性
- rent 属性置为 null
- safe 通 过 newUnsafe() 实 例 化 一 个 unsafe 对 象 , 它 的 类 型 是AbstractNioByteChannel.NioByteUnsafe 内部类
- peline 是 new DefaultChannelPipeline(this) 新创建的实例. 这里体现了:Each Chnnel has its own pipeline and it is created automatically when a new channel is created.
- AbstractNioChannel 中的属性:
- SelectableChannel ch 被 设 置 为 Java SocketChannel, 即NioSocketChannel.newSocket 返回的 Java NIO SocketChannel.
- readInterestOp 被设置为 SelectionKey.OP_READ SelectableChannel ch 被配置为非阻塞的 ch.configureBlocking(false)
- NioSocketChannel 中的属性:
- SocketChannelConfig config = new NioSocketChannelConfig(this,socket.socket())
关于unsafe字段的初始化
我们简单地提到了, 在实例化 NioSocketChannel 的过程中, 会在父类 AbstractChannel 的构
造器中, 调用 newUnsafe() 来获取一个 unsafe 实例. 那么 unsafe 是怎么初始化的呢? 它的
作用是什么?
其实 unsafe 特别关键, 它封装了对 Java 底层 Socket 的操作, 因此实际上是沟通 Netty 上
层和 Java 底层的重要的桥梁.
那么我们就来看一下 Unsafe 接口所提供的方法吧:
1 | interface Unsafe { |
一看便知, 这些方法其实都会对应到相关的 Java 底层的 Socket 的操作.
回到 AbstractChannel 的构造方法中, 在这里调用了 newUnsafe() 获取一个新的 unsafe 对
象, 而 newUnsafe 方法在 NioSocketChannel 中被重写了:
1 | protected AbstractNioUnsafe newUnsafe() { |
NioSocketChannel.newUnsafe 方法会返回一个 NioSocketChannelUnsafe 实例. 从这里我们就可以确定 了,在实例化的NioSocketChannel中的unsafe字段,其实是一个NioSocketChannelUnsafe 的实例.
关于pipeline的初始化
上面我们分析了一个 Channel (在这个例子中是 NioSocketChannel) 的大体初始化过程, 但是我们漏掉
了一个关键的部分, 即 ChannelPipeline 的初始化.
根据 Each channel has its own pipeline and it is created automatically when a new channel is
created., 我们知道, 在实例化一个 Channel 时, 必然伴随着实例化一个 ChannelPipeline. 而我们确
实在 AbstractChannel 的构造器看到了 pipeline 字段被初始化为 DefaultChannelPipeline 的实例.
那么我们就来看一下, DefaultChannelPipeline 构造器做了哪些工作吧:
1 | protected DefaultChannelPipeline(Channel channel) { |
我们调用 DefaultChannelPipeline 的构造器, 传入了一个 channel, 而这个 channel 其实就是我们实
例化的 NioSocketChannel, DefaultChannelPipeline 会将这个 NioSocketChannel 对象保存在 channel
字段中. DefaultChannelPipeline 中, 还有两个特殊的字段, 即 head 和 tail, 而这两个字段是一个双
向链表的头和尾. 其实在 DefaultChannelPipeline 中, 维护了一个以 AbstractChannelHandlerContext
为节点的双向链表, 这个链表是 Netty 实现 Pipeline 机制的关键. 关于 DefaultChannelPipeline 中
的双向链表以及它所起的作用,这一节我们暂时不做详细分析。先看看 HeadContext 的继承层次结构如下所示: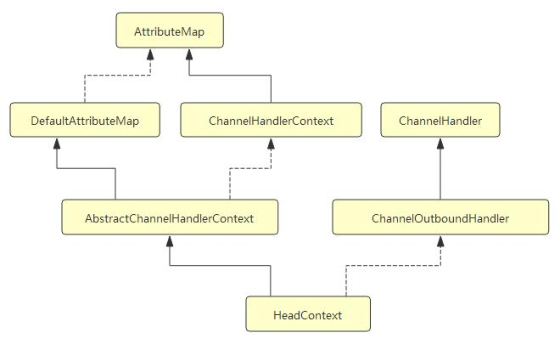
TailContext 的继承层次结构如下所示: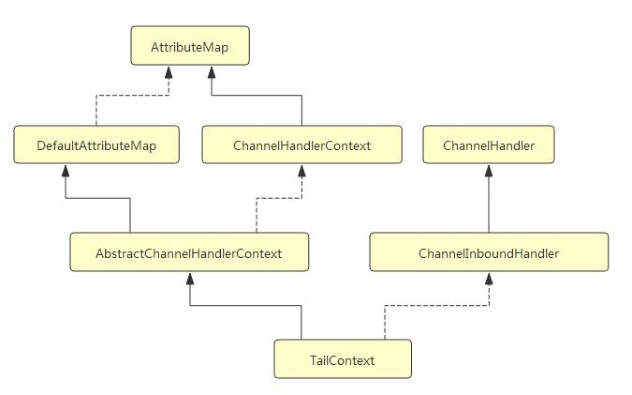
我 们 可 以 看 到 , 链 表 中 head 是 一 个 ChannelOutboundHandler, 而 tail 则 是 一 个
ChannelInboundHandler.
接着看一下 HeadContext 的构造器:
1 | HeadContext(DefaultChannelPipeline pipeline) { |
它调用了父类 AbstractChannelHandlerContext 的构造器, 并传入参数 inbound = false,
outbound = true.
TailContext 的 构 造 器 与 HeadContext 的 相 反 , 它 调 用 了 父 类
AbstractChannelHandlerContext 的构造器, 并传入参数 inbound = true, outbound = false.
即 header 是一个 outboundHandler, 而 tail 是一个 inboundHandler, 关于这一点, 大家要
特别注意, 因为在分析到 Netty Pipeline 时, 我们会反复用到 inbound 和 outbound 这两个
属性.
关于EventLoop的初始化
回到最开始的 ChatClient.java 代码中, 我们在一开始就实例化了一个 NioEventLoopGroup
对象, 因此我们就从它的构造器中追踪一下 EventLoop 的初始化过程.首先来看一下 NioEventLoopGroup 的类继承层次: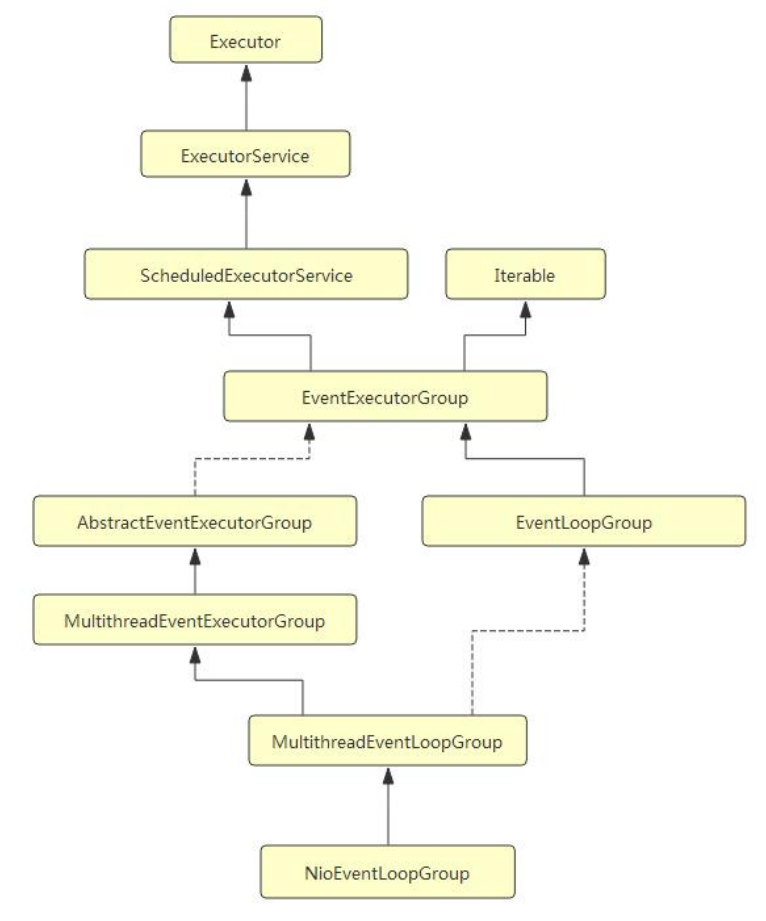
NioEventLoop 有几个重载的构造器, 不过内容都没有什么大的区别, 最终都是调用的父类
MultithreadEventLoopGroup 构造器:
1 | protected MultithreadEventLoopGroup(int nThreads, Executor executor, Object... args) |
其中有一点有意思的地方是, 如果我们传入的线程数 nThreads 是 0, 那么 Netty 会为我们设
置默认的线程数 DEFAULT_EVENT_LOOP_THREADS, 而这个默认的线程数是怎么确定的呢?
其实很简单, 在静态代码块中, 会首先确定 DEFAULT_EVENT_LOOP_THREADS 的值:
1 | static { |
Netty 会首先从系统属性中获取 “io.netty.eventLoopThreads” 的值, 如果我们没有设置它的
话, 那么就返回默认值: 处理器核心数 * 2.
回 到 MultithreadEventLoopGroup 构 造 器 中 , 这 个 构 造 器 会 继 续 调 用 父 类
MultithreadEventExecutorGroup 的构造器:
1 | protected MultithreadEventExecutorGroup(int nThreads, Executor executor, |
根据代码, 我们就很清楚 MultithreadEventExecutorGroup 中的处理逻辑了:
- 创建一个大小为 nThreads 的 SingleThreadEventExecutor 数组
- 根据 nThreads 的大小, 创建不同的 Chooser, 即如果 nThreads 是 2 的幂, 则使用PowerOfTwoEventExecutorChooser, 反之使用 GenericEventExecutorChooser. 不论使用哪个Chooser, 它们的功能都是一样的, 即从 children 数组中选出一个合适的 EventExecutor 实例.
- 调用 newChhild 方法初始化 children 数组.根 据 上 面 的 代 码 , 我 们 知 道 , MultithreadEventExecutorGroup 内 部 维 护 了 一 个EventExecutor 数 组 , Netty 的 EventLoopGroup 的 实 现 机 制 其 实 就 建 立 在MultithreadEventExecutorGroup 之上. 每当 Netty 需要一个 EventLoop 时, 会调用 next()方法获取一个可用的 EventLoop.
上面代码的最后一部分是 newChild 方法, 这个是一个抽象方法, 它的任务是实例化
EventLoop 对象. 我们跟踪一下它的代码, 可以发现, 这个方法在 NioEventLoopGroup 类中实
现了, 其内容很简单:
1 | protected EventLoop newChild(Executor executor, Object... args) throws Exception { |
其实就是实例化一个 NioEventLoop 对象, 然后返回它.
最后总结一下整个 EventLoopGroup 的初始化过程吧:
- EventLoopGroup(其实是 MultithreadEventExecutorGroup) 内部维护一个类型为EventExecutor children 数组, 其大小是 nThreads, 这样就构成了一个线程池
- 如果我们在实例化 NioEventLoopGroup 时, 如果指定线程池大小, 则 nThreads 就是指定的值, 反之是处理器核心数 * 2
- MultithreadEventExecutorGroup 中会调用 newChild 抽象方法来初始化 children 数组
- 抽象方法 newChild 是在 NioEventLoopGroup 中实现的, 它返回一个 NioEventLoop实例.
- NioEventLoop 属性:
- SelectorProvider provider 属 性 : NioEventLoopGroup 构 造 器 中 通 过SelectorProvider.provider() 获取一个 SelectorProvider
- Selector selector 属性: NioEventLoop 构造器中通过调用通过 selector =provider.openSelector() 获取一个 selector 对象.
Channel的注册过程
在前面的分析中, 我们提到, channel 会在 Bootstrap.initAndRegister 中进行初始化, 但是
这个方法还会将初始化好的 Channel 注册到 EventGroup 中. 接下来我们就来分析一下
Channel 注册的过程.
回顾一下 AbstractBootstrap.initAndRegister 方法:
1 | final ChannelFuture initAndRegister() { |
当 Channel 初始化后, 会紧接着调用 group().register() 方法来注册 Channel, 我们继续跟
踪的话, 会发现其调用链如下:
AbstractBootstrap.initAndRegister -> MultithreadEventLoopGroup.register ->
SingleThreadEventLoop.register -> AbstractChannelAbstractUnsafe.register 方法中到底做了什么:
1 | public final void register(EventLoop eventLoop, final ChannelPromise promise) { |
首先, 将 eventLoop 赋值给 Channel 的 eventLoop 属性, 而我们知道这个 eventLoop 对象
其实是 MultithreadEventLoopGroup.next() 方法获取的, 根据我们前面的小节中, 我们可以
确定 next() 方法返回的 eventLoop 对象是 NioEventLoop 实例.
register 方法接着调用了 register0 方法:
1 | private void register0(ChannelPromise promise) { |
register0 又调用了 AbstractNioChannel.doRegister:
1 | protected void doRegister() throws Exception { |
javaChannel() 这个方法在前面我们已经知道了, 它返回的是一个 Java NIO SocketChannel,
这里我们将这个 SocketChannel 注册到与 eventLoop 关联的 selector 上了.
我们总结一下 Channel 的注册过程:
- 首先在 AbstractBootstrap.initAndRegister 中, 通过 group().register(channel),调用 MultithreadEventLoopGroup.register 方法
- 在 MultithreadEventLoopGroup.register 中 , 通 过 next() 获 取 一 个 可 用 的SingleThreadEventLoop, 然后调用它的 register
- 在 SingleThreadEventLoop.register 中, 通过 channel.unsafe().register(this,promise) 来获取 channel 的 unsafe() 底层操作对象, 然后调用它的 register.
- 在 AbstractUnsafe.register 方法中, 调用 register0 方法注册 Channel
- 在 AbstractUnsafe.register0 中, 调用 AbstractNioChannel.doRegister 方法
- AbstractNioChannel.doRegister 方法通过javaChannel().register(eventLoop().selector, 0, this) 将 Channel 对应的 Java NIOSockerChannel 注册到一个 eventLoop 的 Selector 中, 并且将当前 Channel 作为attachment.
总的来说, Channel 注册过程所做的工作就是将 Channel 与对应的 EventLoop 关联, 因此这
也体现了, 在 Netty 中, 每个 Channel 都会关联一个特定的 EventLoop, 并且这个 Channel
中的所有 IO 操作都是在这个 EventLoop 中执行的; 当关联好 Channel 和 EventLoop 后, 会
继续调用底层的 Java NIO SocketChannel 的 register 方法 , 将底层的 Java NIO
SocketChannel 注册到指定的 selector 中. 通过这两步, 就完成了 Netty Channel 的注册过程.
Handler的添加过程
Netty 的一个强大和灵活之处就是基于 Pipeline 的自定义 handler 机制. 基于此, 我们可以
像添加插件一样自由组合各种各样的 handler 来完成业务逻辑. 例如我们需要处理 HTTP 数据,
那么就可以在 pipeline 前添加一个 Http 的编解码的 Handler, 然后接着添加我们自己的业
务逻辑的 handler, 这样网络上的数据流就向通过一个管道一样, 从不同的 handler 中流过并
进行编解码, 最终在到达我们自定义的 handler 中.
既然说到这里, 有些同学肯定会好奇, 既然这个 pipeline 机制是这么的强大, 那么它是怎么
实现的呢? 在这里我还不打算详细讲解, 在这一小节中, 我们从简单的入手, 展示一下我们自
定义的 handler 是如何以及何时添加到 ChannelPipeline 中的.首先让我们看一下如下的代码片段:
1 | // ... |
这个代码片段就是实现了 handler 的添加功能. 我们看到, Bootstrap.handler 方法接收一个
ChannelHandler, 而我们传递的是一个 派生于 ChannelInitializer 的匿名类, 它正好也实现
了 ChannelHandler 接口. 我们来看一下, ChannelInitializer 类内到底有什么玄机:
1 | public abstract class ChannelInitializer<C extends Channel> extends |
ChannelInitializer 是一个抽象类, 它有一个抽象的方法 initChannel, 我们正是实现了这个
方法, 并在这个方法中添加的自定义的 handler 的. 那么 initChannel 是哪里被调用的呢?
答案是 ChannelInitializer.channelRegistered 方法中.
我 们 来 关 注 一 下 channelRegistered 方 法 . 从 上 面 的 源 码 中 , 我 们 可 以 看 到 , 在
channelRegistered 方法中, 会调用 initChannel 方法, 将自定义的 handler 添加到
ChannelPipeline 中, 然后调用 ctx.pipeline().remove(this) 将自己从 ChannelPipeline
中删除. 上面的分析过程, 可以用如下图片展示:
一 开 始 , ChannelPipeline 中 只 有 三 个 handler, head, tail 和 我 们 添 加 的
ChannelInitializer.
接着 initChannel 方法调用后, 添加了自定义的 handler:
最后将 ChannelInitializer 删除:
分析到这里, 我们已经简单了解了自定义的 handler 是如何添加到 ChannelPipeline 中
的, 在后面的我们再进行深入的探讨.
客户端连接分析
经过上面的各种分析后, 我们大致了解了 Netty 初始化时, 所做的工作, 那么接下来我们就直
奔主题, 分析一下客户端是如何发起 TCP 连接的.
首先, 客户端通过调用 Bootstrap 的 connect 方法进行连接.
在 connect 中, 会进行一些参数检查后, 最终调用的是 doConnect 方法, 其实现如下:
1 | private static void doConnect( |
在 doConnect 中, 会在 event loop 线程中调用 Channel 的 connect 方法, 而这个 Channel
的 具 体 类 型 是 什 么 呢 ? 我 们 在 前 面 已 经 分 析 过 了 , 这 里 channel 的 类 型 就 是
NioSocketChannel.
进行跟踪到 channel.connect 中, 我们发现它调用的是 DefaultChannelPipeline.connect,
而, pipeline 的 connect 代码如下:
1 | public final ChannelFuture connect(SocketAddress remoteAddress, ChannelPromise promise) |
而 tail 字段, 我们已经分析过了, 是一个 TailContext 的实例, 而 TailContext 又是
AbstractChannelHandlerContext 的子类, 并且没有实现 connect 方法, 因此这里调用的其实
是 AbstractChannelHandlerContext.connect, 我们看一下这个方法的实现:
1 | public ChannelFuture connect( |
上 面 的 代 码 中 有 一 个 关 键 的 地 方 , 即 final AbstractChannelHandlerContext next =
findContextOutbound(), 这里调用 findContextOutbound 方法, 从 DefaultChannelPipeline
内 的 双 向 链 表 的 tail 开 始 , 不 断 向 前 寻 找 第 一 个 outbound 为 true 的
AbstractChannelHandlerContext, 然后调用它的 invokeConnect 方法, 其代码如下:
1 | private void invokeConnect(SocketAddress remoteAddress, SocketAddress localAddress, |
前面我们提到, 在 DefaultChannelPipeline 的构造器中, 会实例化两个对象: head 和 tail,
并 形 成 了 双 向 链 表 的 头 和 尾 . head 是 HeadContext 的 实 例 , 它 实 现 了
ChannelOutboundHandler 接 口 , 并 且 它 的 outbound 字 段 为 true. 因 此 在
findContextOutbound 中, 找到的 AbstractChannelHandlerContext 对象其实就是 head. 进
而在 invokeConnect 方法中, 我们向上转换为 ChannelOutboundHandler 就是没问题的了.
而又因为 HeadContext 重写了 connect 方法, 因此实际上调用的是 HeadContext.connect.
我们接着跟踪到 HeadContext.connect, 其代码如下:
1 | public void connect( |
这个 connect 方法很简单, 仅仅调用了 unsafe 的 connect 方法. 而 unsafe 又是什么呢?
回顾一下 HeadContext 的构造器, 我们发现 unsafe 是 pipeline.channel().unsafe() 返回
的 是 Channel 的 unsafe 字 段 , 在 这 这 里 , 我 们 已 经 知 道 了 , 其 实 是
AbstractNioByteChannel.NioByteUnsafe 内部类. 兜兜转转了一大圈, 我们找到了创建
Socket 连接的关键代码.
进行跟踪 NioByteUnsafe -> AbstractNioUnsafe.connect:
1 | public final void connect( |
AbstractNioUnsafe.connect 的实现如上代码所示, 在这个 connect 方法中, 调用了
doConnect 方 法 , 注 意 , 这 个 方 法 并 不 是 AbstractNioUnsafe 的 方 法 , 而 是
AbstractNioChannel 的抽象方法. doConnect 方法是在 NioSocketChannel 中实现的, 因此进
入到 NioSocketChannel.doConnect 中:
1 | protected boolean doConnect(SocketAddress remoteAddress, SocketAddress localAddress) |
我们终于看到的最关键的部分了, 庆祝一下!
上面的代码不用多说, 首先是获取 Java NIO SocketChannel, 从 NioSocketChannel.newSocket
返回的 SocketChannel 对象; 然后是调用 SocketChannel.connect 方法完成 Java NIO 层面
上的 Socket 的连接.
最后, 上面的代码流程可以用如下时序图直观地展示: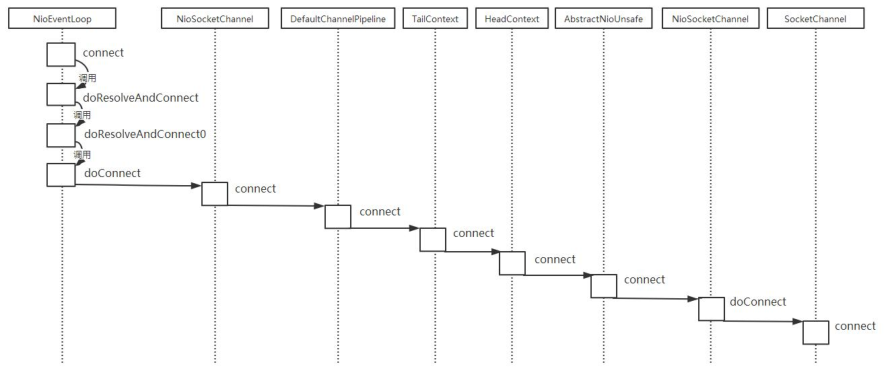
服务端ServerBootStrap
在分析客户端的代码时, 我们已经对 Bootstrap 启动 Netty 有了一个大致的认识, 那么接下
来分析服务器端时, 就会相对简单一些了.
首先还是来看一下服务器端的启动代码:
1 | public class ChatServer { |
和客户端的代码相比, 没有很大的差别, 基本上也是进行了如下几个部分的初始化:
- EventLoopGroup: 不论是服务器端还是客户端, 都必须指定 EventLoopGroup. 在这个例子中, 指定了 NioEventLoopGroup, 表示一个 NIO 的 EventLoopGroup, 不过服务器端需要指定两个 EventLoopGroup, 一个是 bossGroup, 用于处理客户端的连接请求; 另一个是workerGroup, 用于处理与各个客户端连接的 IO 操作.
- ChannelType: 指 定 Channel 的 类 型 . 因 为 是 服 务 器 端 , 因 此 使 用 了NioServerSocketChannel.
- Handler: 设置数据的处理器.
Channel的初始化过程
我们在分析客户端的 Channel 初始化过程时, 已经提到, Channel 是对 Java 底层 Socket 连接的抽象,
并且知道了客户端的 Channel 的具体类型是 NioSocketChannel, 那么自然的, 服务器端的 Channel 类型就是 NioServerSocketChannel 了.
那么接下来我们按照分析客户端的流程对服务器端的代码也同样地分析一遍, 这样也方便我们对比一下服
务器端和客户端有哪些不一样的地方.
Channel类型的确定
同样的分析套路, 我们已经知道了, 在客户端中, Channel 的类型其实是在初始化时, 通过
Bootstrap.channel() 方法设置的, 服务器端自然也不例外.
在服务器端, 我们调用了 ServerBootstarap.channel(NioServerSocketChannel.class), 传递了一个
NioServerSocketChannel Class 对象. 这样的话, 按照和分析客户端代码一样的流程, 我们就可以确定,
NioServerSocketChannel 的 实 例 化 是 通 过 ReflectiveChannelFactory 工 厂 类 来 完 成 的 , 而ReflectiveChannelFactory 中的 clazz 字段被设置为了 NioServerSocketChannel.class, 因此当调用
ReflectiveChannelFactory.newChannel() 时:
1 | public T newChannel() { |
就获取到了一个 NioServerSocketChannel 的实例.
最后我们也来总结一下:
- ServerBootstrap 中的 ChannelFactory 的实现是 ReflectiveChannelFactory
- 生成的 Channel 的具体类型是 NioServerSocketChannel.
Channel 的实例化过程, 其实就是调用的 ChannelFactory.newChannel 方法, 而实例化的 Channel的具体的类型又是和在初始化 ServerBootstrap 时传入的 channel() 方法的参数相关. 因此对于我们这
个例子中的服务器端的 ServerBootstrap 而言, 生成的的 Channel 实例就是 NioServerSocketChannel.
NioServerSocketChannel 的实例化过程
首先还是来看一下 NioServerSocketChannel 的实例化过程.
下面是 NioServerSocketChannel 的类层次结构图: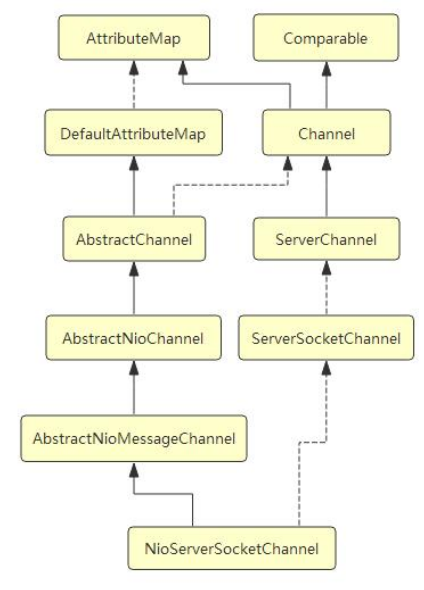
首先, 我们来看一下它的默认的构造器. 和 NioSocketChannel 类似, 构造器都是调用了 newSocket 来
打开一个 Java 的 NIO Socket, 不过需要注意的是, 客户端的 newSocket 调用的是 openSocketChannel,
而服务器端的 newSocket 调用的是 openServerSocketChannel. 顾名思义, 一个是客户端的 Java SocketChannel, 一个是服务器端的 Java ServerSocketChannel.
1 | private static ServerSocketChannel newSocket(SelectorProvider provider) { |
接下来会调用重载的构造器:
1 | public NioServerSocketChannel(ServerSocketChannel channel) { |
这个构造其中, 调用父类构造器时, 传入的参数是 SelectionKey.OP_ACCEPT. 作为对比, 我们回想一下,
在客户端的 Channel 初始化时, 传入的参数是 SelectionKey.OP_READ. 我前面讲过, Java NIO 是一种
Reactor 模式, 我们通过 selector 来实现 I/O 的多路复用复用. 在一开始时, 服务器端需要监听客户
端的连接请求, 因此在这里我们设置了 SelectionKey.OP_ACCEPT, 即通知 selector 我们对客户端的连接请求感兴趣.
接 着 和 客 户 端 的 分 析 一 下 , 会 逐 级 地 调 用 父 类 的 构 造 器 NioServerSocketChannel ->
AbstractNioMessageChannel -> AbstractNioChannel -> AbstractChannel.
同样的, 在 AbstractChannel 中会实例化一个 unsafe 和 pipeline:
1 | protected AbstractChannel(Channel parent) { |
不过, 这里有一点需要注意的是, 客户端的 unsafe 是一个 AbstractNioByteChannel#NioByteUnsafe 的
实例, 而在服务器端时, 因为 AbstractNioMessageChannel 重写了 newUnsafe 方法:
1 | protected AbstractNioUnsafe newUnsafe() { |
因此在服务器端, unsafe 字段其实是一个 AbstractNioMessageChannel.AbstractNioUnsafe 的实例.我们来总结一下, 在 NioServerSocketChannsl 实例化过程中, 所需要做的工作:
- 调用 NioServerSocketChannel.newSocket(DEFAULT_SELECTOR_PROVIDER) 打开一个新的 Java NIO ServerSocketChannel
- AbstractChannel(Channel parent) 中初始化 AbstractChannel 的属性:
- parent 属性置为 null
- unsafe 通 过 newUnsafe() 实 例 化 一 个 unsafe 对 象 , 它 的 类 型 是AbstractNioMessageChannel#AbstractNioUnsafe 内部类
- pipeline 是 new DefaultChannelPipeline(this) 新创建的实例.
- AbstractNioChannel 中的属性:
- SelectableChannel ch 被 设 置 为 Java ServerSocketChannel, 即NioServerSocketChannel#newSocket 返回的 Java NIO ServerSocketChannel.
- readInterestOp 被设置为 SelectionKey.OP_ACCEPT
- SelectableChannel ch 被配置为非阻塞的 ch.configureBlocking(false)
- NioServerSocketChannel 中的属性:
- ServerSocketChannelConfig config = new NioServerSocketChannelConfig(this,javaChannel().socket())
ChannelPipeline 初始化
服务器端和客户端的 ChannelPipeline 的初始化一致, 因此就不再单独分析了.
Channel的注册
服务器端和客户端的 Channel 的注册过程一致, 因此就不再单独分析了.
关于bossGroup与workerGroup
在客户端的时候, 我们只提供了一个 EventLoopGroup 对象, 而在服务器端的初始化时, 我们设置了两个
EventLoopGroup, 一个是 bossGroup, 另一个是 workerGroup. 那么这两个 EventLoopGroup 都是干什么
用的呢? 其实呢, bossGroup 是用于服务端 的 accept 的, 即用于处理客户端的连接请求. 我们可以把
Netty 比作一个饭店, bossGroup 就像一个像一个前台接待, 当客户来到饭店吃时, 接待员就会引导顾客
就坐, 为顾客端茶送水等. 而 workerGroup, 其实就是实际上干活的啦, 它们负责客户端连接通道的 IO
操作: 当接待员 招待好顾客后, 就可以稍做休息, 而此时后厨里的厨师们(workerGroup)就开始忙碌地准
备饭菜了.
关于 bossGroup 与 workerGroup 的关系, 我们可以用如下图来展示: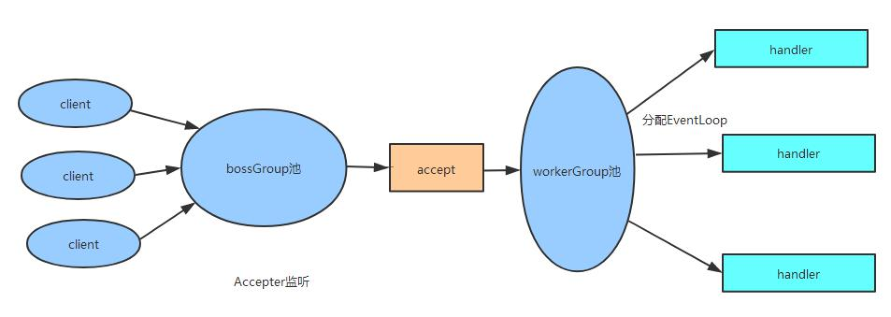
首先, 服务器端 bossGroup 不断地监听是否有客户端的连接, 当发现有一个新的客户端连接到来时,
bossGroup 就会为此连接初始化各项资源, 然后从 workerGroup 中选出一个 EventLoop 绑定到此客户端
连接中. 那么接下来的服务器与客户端的交互过程就全部在此分配的 EventLoop 中了.
口说无凭, 我们还是以源码说话吧.
首 先 在 ServerBootstrap 初 始 化 时 , 调 用 了 b.group(bossGroup, workerGroup) 设 置 了 两 个
EventLoopGroup, 我们跟踪进去看一下:
1 | public ServerBootstrap group(EventLoopGroup parentGroup, EventLoopGroup childGroup) { |
显然, 这个方法初始化了两个字段, 一个是 group = parentGroup, 它是在 super.group(parentGroup)
中初始化的, 另一个是 childGroup = childGroup. 接着我们启动程序调用了 b.bind 方法来监听一个本
地端口. bind 方法会触发如下的调用链:
AbstractBootstrap.bind -> AbstractBootstrap.doBind ->
AbstractBootstrap.initAndRegister
源码看到到这里为止,AbstractBootstrap.initAndRegister 已经是我们的老朋友了, 我们在分析客户端
程序时, 和它打过很多交到了, 现在再来回顾一下这个方法吧:
1 | final ChannelFuture initAndRegister() { |
这里 group() 方法返回的是上面我们提到的 bossGroup, 而这里的 channel 我们也已经分析过了, 它是
一个 NioServerSocketChannsl 实例, 因此我们可以知道, group().register(channel) 将 bossGroup
和 NioServerSocketChannsl 关联起来了.
那么 workerGroup 是在哪里与 NioServerSocketChannel 关联的呢?
我们继续看 init(channel) 方法:
1 | void init(Channel channel) throws Exception { |
init 方法在 ServerBootstrap 中重写了, 从上面的代码片段中我们看到, 它为 pipeline 中添加了一个
ChannelInitializer, 而这个 ChannelInitializer 中添加了一个关键的 ServerBootstrapAcceptor
handler. 关于 handler 的添加与初始化的过程, 我们留待下一小节中分析, 我们现在关注一下
ServerBootstrapAcceptor 类.
ServerBootstrapAcceptor 中重写了 channelRead 方法, 其主要代码如下:
1 | public void channelRead(ChannelHandlerContext ctx, Object msg) { |
ServerBootstrapAcceptor 中的 childGroup 是构造此对象是传入的 currentChildGroup, 即我们的
workerGroup, 而 Channel 是一个 NioSocketChannel 的实例, 因此这里的 childGroup.register 就是
将 workerGroup 中的某个 EventLoop 和 NioSocketChannel 关联了. 既然这样, 那么现在的问题是,
ServerBootstrapAcceptor.channelRead 方法是怎么被调用的呢? 其实当一个 client 连接到 server 时,
Java 底层的 NIO ServerSocketChannel 会有一个 SelectionKey.OP_ACCEPT 就绪事件, 接着就会调用到
NioServerSocketChannel.doReadMessages:
1 | protected int doReadMessages(List<Object> buf) throws Exception { |
在 doReadMessages 中, 通过 javaChannel().accept() 获取到客户端新连接的 SocketChannel, 接着就
实例化一个 NioSocketChannel, 并且传入 NioServerSocketChannel 对象(即 this), 由此可知, 我们创
建的这个 NioSocketChannel 的父 Channel 就是 NioServerSocketChannel 实例 .
接下来就经由 Netty 的 ChannelPipeline 机制, 将读取事件逐级发送到各个 handler 中, 于是就会触
发前面我们提到的 ServerBootstrapAcceptor.channelRead 方法啦.
Handler 的添加过程
服务器端的 handler 的添加过程和客户端的有点区别, 和 EventLoopGroup 一样, 服务器端的 handler
也有两个, 一个是通过 handler() 方法设置 handler 字段, 另一个是通过 childHandler() 设置
childHandler 字段. 通过前面的 bossGroup 和 workerGroup 的分析, 其实我们在这里可以大胆地猜测:
handler 字段与 accept 过程有关, 即这个 handler 负责处理客户端的连接请求; 而 childHandler 就
是负责和客户端的连接的 IO 交互.
那么实际上是不是这样的呢? 来, 我们继续通过代码证明.
在 关于 bossGroup 与 workerGroup 小节中, 我们提到, ServerBootstrap 重写了 init 方法, 在这个
方法中添加了 handler:
1 | void init(Channel channel) throws Exception { |
上面代码的 initChannel 方法中, 首先通过 handler() 方法获取一个 handler, 如果获取的 handler
不为空,则添加到 pipeline 中. 然后接着, 添加了一个 ServerBootstrapAcceptor 实例. 那么这里
handler() 方法返回的是哪个对象呢? 其实它返回的是 handler 字段, 而这个字段就是我们在服务器端
的启动代码中设置的:
1 | b.group(bossGroup, workerGroup) |
那么这个时候, pipeline 中的 handler 情况如下:
根据我们原来分析客户端的经验, 我们指定, 当 channel 绑定到 eventLoop 后(在这里是
NioServerSocketChannel 绑 定 到 bossGroup) 中 时 , 会 在 pipeline 中 发 出
fireChannelRegistered 事件, 接着就会触发 ChannelInitializer.initChannel 方法的调用.
因此在绑定完成后, 此时的 pipeline 的内如下:
前 面 我 们 在 分 析 bossGroup 和 workerGroup 时 , 已 经 知 道 了 在
ServerBootstrapAcceptor.channelRead 中会为新建的 Channel 设置 handler 并注册到一个
eventLoop 中, 即:
1 | public void channelRead(ChannelHandlerContext ctx, Object msg) { |
而这里的 childHandler 就是我们在服务器端启动代码中设置的 handler:
1 | // ... |
后续的步骤就没有什么好说的了, 当这个客户端连接 Channel 注册后, 就会触发
ChannelInitializer.initChannel 方法的调用。
最后我们来总结一下服务器端的 handler 与 childHandler 的区别与联系:
- 在 服 务 器 NioServerSocketChannel 的 pipeline 中 添 加 的 是 handler 与ServerBootstrapAcceptor.
- 当有新的客户端连接请求时, ServerBootstrapAcceptor.channelRead 中负责新建此连接的 NioSocketChannel 并添加 childHandler 到 NioSocketChannel 对应的 pipeline 中,并将此 channel 绑定到 workerGroup 中的某个 eventLoop 中.
- handler 是在 accept 阶段起作用, 它处理客户端的连接请求.
- childHandler 是在客户端连接建立以后起作用, 它负责客户端连接的 IO 交互.
Netty的关键ChannelPipeline
ChannelPipeline
Channel和ChannelPipeline
相信大家都知道了, 在 Netty 中每个 Channel 都有且仅有一个 ChannelPipeline 与之对应,
它们的组成关系如下: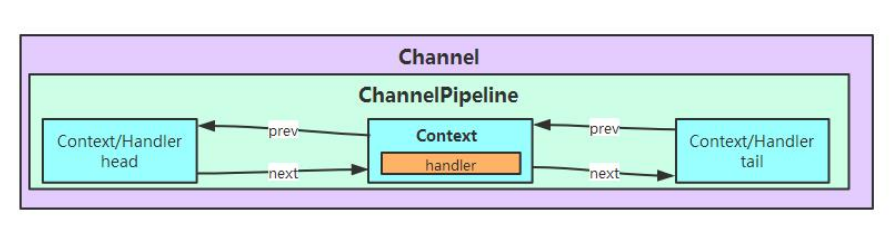
通过上图我们可以看到, 一个 Channel 包含了一个 ChannelPipeline, 而 ChannelPipeline
中又维护了一个由 ChannelHandlerContext 组成的双向链表. 这个链表的头是 HeadContext,
链 表 的 尾 是 TailContext, 并 且 每 个 ChannelHandlerContext 中 又 关 联 着 一 个
ChannelHandler.
上面的图示给了我们一个对 ChannelPipeline 的直观认识, 但是实际上 Netty 实现的
Channel 是否真的是这样的呢? 我们继续用源码说话.
在前我们已经知道了一个 Channel 的初始化的基本过程, 下面我们再回顾一下.
下面的代码是 AbstractChannel 构造器:
1 | protected AbstractChannel(Channel parent) { |
AbstractChannel 有一个 pipeline 字段, 在构造器中会初始化它为 DefaultChannelPipeline
的实例. 这里的代码就印证了一点: 每个 Channel 都有一个 ChannelPipeline.
接着我们跟踪一下 DefaultChannelPipeline 的初始化过程.
首先进入到 DefaultChannelPipeline 构造器中:
1 | protected DefaultChannelPipeline(Channel channel) { |
在 DefaultChannelPipeline 构造器中, 首先将与之关联的 Channel 保存到字段 channel 中,
然后实例化两个 ChannelHandlerContext, 一个是 HeadContext 实例 head, 另一个是
TailContext 实例 tail. 接着将 head 和 tail 互相指向, 构成一个双向链表.
特别注意到, 我们在开始的示意图中, head 和 tail 并没有包含 ChannelHandler, 这是因为
HeadContext 和 TailContext 继承于 AbstractChannelHandlerContext 的同时也实现了
ChannelHandler 接口了, 因此它们有 Context 和 Handler 的双重属性.
ChannelPipeline的初始化
前面 我们已经对 ChannelPipeline 的初始化有了一个大致的了解, 不过当时重点毕竟不在
ChannelPipeline 这里, 因此没有深入地分析它的初始化过程. 那么下面我们就来看一下具体
的 ChannelPipeline 的初始化都做了哪些工作吧.
先回顾一下, 在实例化一个 Channel 时, 会伴随着一个 ChannelPipeline 的实例化, 并且此
Channel 会与这个 ChannelPipeline 相互关联, 这一点可以通过 NioSocketChannel 的父类
AbstractChannel 的构造器予以佐证:
1 | protected AbstractChannel(Channel parent) { |
当实例化一个 Channel(这里以 EchoClient 为例, 那么 Channel 就是 NioSocketChannel),
其 pipeline 字段就是我们新创建的 DefaultChannelPipeline 对象, 那么我们就来看一下
DefaultChannelPipeline 的构造方法吧:
1 | protected DefaultChannelPipeline(Channel channel) { |
可以看到, 在 DefaultChannelPipeline 的构造方法中, 将传入的 channel 赋值给字段
this.channel, 接着又实例化了两个特殊的字段: tail 与 head. 这两个字段是一个双向链表
的 头 和 尾 . 其 实 在 DefaultChannelPipeline 中 , 维 护 了 一 个 以
AbstractChannelHandlerContext 为节点的双向链表, 这个链表是 Netty 实现 Pipeline 机制
的关键.
再回顾一下 head 和 tail 的类层次结构: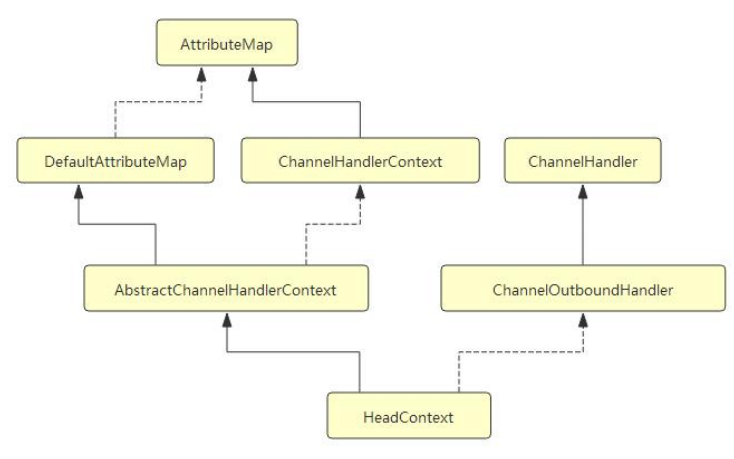
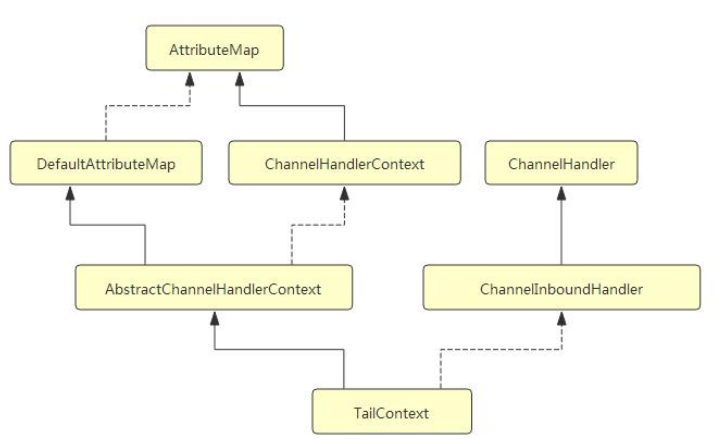
从类层次结构图中可以很清楚地看到, head 实现了 ChannelInboundHandler, 而 tail 实现了
ChannelOutboundHandler 接口, 并且它们都实现了 ChannelHandlerContext 接口, 因此可以
说 head 和 tail 即是一个 ChannelHandler, 又是一个 ChannelHandlerContext.
接着看一下 HeadContext 的构造器:
1 | HeadContext(DefaultChannelPipeline pipeline) { |
它调用了父类 AbstractChannelHandlerContext 的构造器, 并传入参数 inbound = false,
outbound = true.
TailContext 的 构 造 器 与 HeadContext 的 相 反 , 它 调 用 了 父 类
AbstractChannelHandlerContext 的构造器, 并传入参数 inbound = true, outbound = false.
即 header 是一个 outboundHandler, 而 tail 是一个 inboundHandler, 关于这一点, 大家要
特别注意, 因为在后面的分析中, 我们会反复用到 inbound 和 outbound 这两个属性.
ChannelInitializer的添加
前面我们已经分析了 Channel 的组成, 其中我们了解到, 最开始的时候 ChannelPipeline 中
含有两个 ChannelHandlerContext(同时也是 ChannelHandler), 但是这个 Pipeline 并不能实
现什么特殊的功能, 因为我们还没有给它添加自定义的 ChannelHandler.
通常来说, 我们在初始化 Bootstrap, 会添加我们自定义的 ChannelHandler, 就以我们熟悉的
ChatClient 来举例吧:
1 | Bootstrap bootstrap = new Bootstrap(); |
上 面 代 码 的 初 始 化 过 程 , 相 信 大 家 都 不 陌 生 . 在 调 用 handler 时 , 传 入 了
ChannelInitializer 对象, 它提供了一个 initChannel 方法供我们初始化 ChannelHandler.
那么这个初始化过程是怎样的呢? 下面我们就来揭开它的神秘面纱.
ChannelInitializer 实现了 ChannelHandler, 那么它是在什么时候添加到 ChannelPipeline
中 的 呢 ? 进 行 了 一 番 搜 索 后 , 我 们 发 现 它 是 在 Bootstrap.init 方 法 中 添 加 到
ChannelPipeline 中的.
1 | void init(Channel channel) throws Exception { |
上面的代码将 handler() 返回的 ChannelHandler 添加到 Pipeline 中, 而 handler() 返回
的是 handler 其实就是我们在初始化 Bootstrap 调用 handler 设置的 ChannelInitializer
实例, 因此这里就是将 ChannelInitializer 插入到了 Pipeline 的末端.此时 Pipeline 的结构如下图所示:
有同学可能就有疑惑了, 我明明插入的是一个 ChannelInitializer 实例, 为什么在
ChannelPipeline 中的双向链表中的元素却是一个 ChannelHandlerContext? 为了解答这个问
题, 我们继续在代码中寻找答案吧.
我们刚才提到, 在 Bootstrap.init 中会调用 p.addLast() 方法, 将 ChannelInitializer 插
入到链表末端:
1 | public final ChannelPipeline addLast(EventExecutorGroup group, String name, |
addLast 有很多重载的方法, 我们关注这个比较重要的方法就可以了.
上面的 addLast 方法中, 首先检查这个 ChannelHandler 的名字是否是重复的, 如果不重复的
话, 则调用 newContext 方法为这个 Handler 创建一个对应的 DefaultChannelHandlerContext
实例, 并与之关联起来(Context 中有一个 handler 属性保存着对应的 Handler 实例).
为了添加一个 handler 到 pipeline 中, 必须把此 handler 包装成 ChannelHandlerContext.
因此在上面的代码中我们可以看到新实例化了一个 newCtx 对象, 并将 handler 作为参数传递
到构造方法中. 那么我们来看一下实例化的 DefaultChannelHandlerContext 到底有什么玄机
吧.
首先看它的构造器:
1 | DefaultChannelHandlerContext( |
DefaultChannelHandlerContext 的构造器中, 调用了两个很有意思的方法: isInbound 与
isOutbound, 这两个方法是做什么的呢?
1 | private static boolean isInbound(ChannelHandler handler) { |
从源码中可以看到, 当一个 handler 实现了 ChannelInboundHandler 接口, 则 isInbound 返
回真; 相似地, 当一个 handler 实现了 ChannelOutboundHandler 接口, 则 isOutbound 就返
回真.
而这两个 boolean 变量会传递到父类 AbstractChannelHandlerContext 中, 并初始化父类的
两个字段: inbound 与 outbound.
那么这里的 ChannelInitializer 所对应的 DefaultChannelHandlerContext 的 inbound 与
inbound 字段分别是什么呢? 那就看一下 ChannelInitializer 到底实现了哪个接口不就行了?
如下是 ChannelInitializer 的类层次结构图: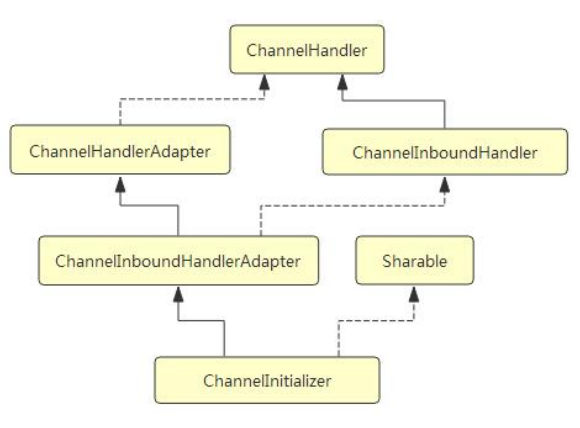
可以清楚地看到, ChannelInitializer 仅仅实现了 ChannelInboundHandler 接口, 因此这里
实例化的 DefaultChannelHandlerContext 的 inbound = true, outbound = false.
不就是 inbound 和 outbound 两个字段嘛, 为什么需要这么大费周章地分析一番? 其实这两个
字段关系到 pipeline 的事件的流向与分类, 因此是十分关键的, 不过我在这里先卖个关子,
后 面 我 们 再 来 详 细 分 析 这 两 个 字 段 所 起 的 作 用 . 在 这 里 , 我 暂 且 只 需 要 记 住 ,
ChannelInitializer 所对应的 DefaultChannelHandlerContext 的 inbound = true, outbound
= false 即可.
当创建好 Context 后, 就将这个 Context 插入到 Pipeline 的双向链表中:
1 | private void addLast0(AbstractChannelHandlerContext newCtx) { |
自定义ChannelHandler的添加过程
前面我们已经分析了一个 ChannelInitializer 如何插入到 Pipeline 中的, 接下来就来探讨
一下 ChannelInitializer 在哪里被调用, ChannelInitializer 的作用, 以及我们自定义的
ChannelHandler 是如何插入到 Pipeline 中的.
现在我们再简单地复习一下 Channel 的注册过程:
- 首先在 AbstractBootstrap.initAndRegister 中, 通过 group().register(channel),调用 MultithreadEventLoopGroup.register 方法
- 在 MultithreadEventLoopGroup.register 中 , 通 过 next() 获 取 一 个 可 用 的SingleThreadEventLoop, 然后调用它的 register
- 在 SingleThreadEventLoop.register 中, 通过 channel.unsafe().register(this,promise) 来获取 channel 的 unsafe() 底层操作对象, 然后调用它的 register.
- 在 AbstractUnsafe.register 方法中, 调用 register0 方法注册 Channel
- 在 AbstractUnsafe.register0 中, 调用 AbstractNioChannel#doRegister 方法
- AbstractNioChannel.doRegister 方法通过javaChannel().register(eventLoop().selector, 0, this) 将 Channel 对应的 Java NIOSockerChannel 注册到一个 eventLoop 的 Selector 中, 并且将当前 Channel 作为attachment.
而我们自定义 ChannelHandler 的添加过程, 发生在 AbstractUnsafe.register0 中, 在
这个方法中调用了 pipeline.fireChannelRegistered() 方法, 其实现如下:
1 | public final ChannelPipeline fireChannelRegistered() { |
再看 AbstractChannelHandlerContext.invokeChannelRegistered 方法:
1 | static void invokeChannelRegistered(final AbstractChannelHandlerContext next) { |
很显然, 这个代码会从 head 开始遍历 Pipeline 的双向链表, 然后找到第一个属性 inbound
为 true 的 ChannelHandlerContext 实 例 . 想 起 来 了 没 ? 我 们 在 前 面 分 析
ChannelInitializer 时, 花了大量的笔墨来分析了 inbound 和 outbound 属性, 你看现在这
里就用上了. 回想一下, ChannelInitializer 实现了 ChannelInboudHandler, 因此它所对应
的 ChannelHandlerContext 的 inbound 属 性 就 是 true, 因 此 这 里 返 回 就 是
ChannelInitializer 实例所对应的 ChannelHandlerContext. 即: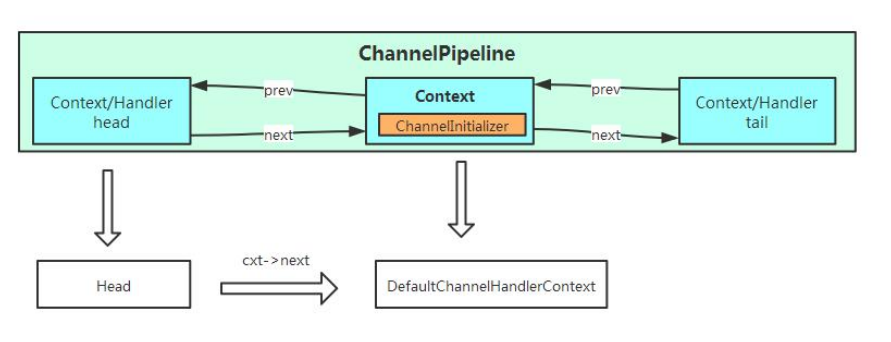
当获取到 inbound 的 Context 后, 就调用它的 invokeChannelRegistered 方法:
1 | private void invokeChannelRegistered() { |
我们已经强调过了, 每个 ChannelHandler 都与一个 ChannelHandlerContext 关联, 我们可以
通过 ChannelHandlerContext 获取到对应的 ChannelHandler. 因此很显然了, 这里 handler()
返 回 的 , 其 实 就 是 一 开 始 我 们 实 例 化 的 ChannelInitializer 对 象 , 并 接 着 调 用 了
ChannelInitializer.channelRegistered 方 法 . 看 到 这 里 , 是 否 会 觉 得 有 点 眼 熟 呢 ?
ChannelInitializer.channelRegistered 这个方法我们在一开始的时候已经大量地接触了, 但
是我们并没有深入地分析这个方法的调用过程, 那么在这里读者朋友应该对它的调用有了更加
深入的了解了吧.
那么这个方法中又有什么玄机呢? 继续看代码:
1 | public final void channelRegistered(ChannelHandlerContext ctx) throws Exception { |
initChannel(© ctx.channel()); 这 个 方 法 我 们 很 熟 悉 了 吧 , 它 就 是 我 们 在 初 始 化
Bootstrap 时, 调用 handler 方法传入的匿名内部类所实现的方法:
1 | .handler(new ChannelInitializer<SocketChannel>() { |
因此当调用了这个方法后, 我们自定义的 ChannelHandler 就插入到 Pipeline 了, 此时的
Pipeline 如下图所示:
当添加了自定义的 ChannelHandler 后, 会删除 ChannelInitializer 这个 ChannelHandler,
即 “ctx.pipeline().remove(this)”, 因此最后的 Pipeline 如下:
好了, 到了这里, 我们的 自定义 ChannelHandler 的添加过程 也分析的查不多了.
ChannelHandler的名字
我们注意到, pipeline.addXXX 都有一个重载的方法, 例如 addLast, 它有一个重载的版本是:
1 | ChannelPipeline addLast(String name, ChannelHandler handler); |
第一个参数指定了所添加的 handler 的名字(更准确地说是 ChannelHandlerContext 的名字,
不过我们通常是以 handler 作为叙述的对象, 因此说成 handler 的名字便于理解). 那么
handler 的名字有什么用呢? 如果我们不设置 name, 那么 handler 会有怎样的名字?
为了解答这些疑惑, 老规矩, 依然是从源码中找到答案.
我们还是以 addLast 方法为例:
1 | public final ChannelPipeline addLast(String name, ChannelHandler handler) { |
这个方法会调用重载的 addLast 方法:
1 | public final ChannelPipeline addLast(EventExecutorGroup group, String name, |
第一个参数被设置为 null, 我们不关心它. 第二参数就是这个 handler 的名字. 看代码可知,
在添加一个 handler 之前, 需要调用 checkMultiplicity 方法来确定此 handler 的名字是否和已添加的 handler 的名字重复.
自动生成handler的名字
如果我们调用的是如下的 addLast 方法
1 | ChannelPipeline addLast(ChannelHandler... handlers); |
那么 Netty 会调用 generateName 为我们的 handler 自动生成一个名字:
1 | private String filterName(String name, ChannelHandler handler) { |
而 generateName 会接着调用 generateName0 来实际产生一个 handler 的名字:
1 | private static String generateName0(Class<?> handlerType) { |
自动生成的名字的规则很简单, 就是 handler 的简单类名加上 “#0”, 因此我们的
ChatClientHandler 的名字就是 “ChatClientHandler#0”
关于Pipeline的事件传播机制
前面章节中, 我们知道 AbstractChannelHandlerContext 中有 inbound 和 outbound 两个
boolean 变量, 分别用于标识 Context 所对应的 handler 的类型, 即:
- inbound 为真时, 表示对应的 ChannelHandler 实现了 ChannelInboundHandler 方法.
- outbound 为真时, 表示对应的 ChannelHandler 实现了 ChannelOutboundHandler 方法.
这里大家肯定很疑惑了吧: 那究竟这两个字段有什么作用呢? 其实这还要从 ChannelPipeline
的传输的事件类型说起.
Netty 的事件可以分为 Inbound 和 Outbound 事件.
从上图可以看出, inbound 事件和 outbound 事件的流向是不一样的, inbound 事件的流行是从
下至上, 而 outbound 刚好相反, 是从上到下. 并且 inbound 的传递方式是通过调用相应的
ChannelHandlerContext.fireIN_EVT() 方法, 而 outbound 方法的的传递方式是通过调用
ChannelHandlerContext.OUT_EVT() 方 法 . 例 如
ChannelHandlerContext.fireChannelRegistered() 调用会发送一个 ChannelRegistered 的
inbound 给下一个 ChannelHandlerContext, 而 ChannelHandlerContext.bind 调用会发送一
个 bind 的 outbound 事件给 下一个 ChannelHandlerContext.
Inbound 事件传播方法有:
1 | public interface ChannelInboundHandler extends ChannelHandler { |
Outbound 事件传输方法有:
1 | public interface ChannelOutboundHandler extends ChannelHandler { |
注意, 如果我们捕获了一个事件, 并且想让这个事件继续传递下去, 那么需要调用 Context 相
应的传播方法.
例如:
1 | public class MyInboundHandler extends ChannelInboundHandlerAdapter { |
上面的例子中, MyInboundHandler 收到了一个 channelActive 事件, 它在处理后, 如果希望
将事件继续传播下去, 那么需要接着调用 ctx.fireChannelActive().
Outbound的操作(outbound operations of a channel)
Outbound 事件都是请求事件(request event), 即请求某件事情的发生, 然后通过 Outbound
事件进行通知.
Outbound 事件的传播方向是 tail -> customContext -> head.
我们接下来以 connect 事件为例, 分析一下 Outbound 事件的传播机制.
首先, 当用户调用了 Bootstrap.connect 方法时, 就会触发一个 t Connect 请求事件, 此调用
会触发如下调用链:
Bootstrap.connect->Bootstrap.doResolveAndConnect->Bootstrap.doResolveAndConnect0->
->Bootstrap.doConnect->AbstractChannel.connect
继续跟踪的话, 我们就发现, AbstractChannel.connect 其实由调用了
DefaultChannelPipeline.connect 方法:
1 | public ChannelFuture connect(SocketAddress remoteAddress, ChannelPromise promise) { |
而 pipeline.connect 的实现如下
1 | public final ChannelFuture connect(SocketAddress remoteAddress, ChannelPromise promise) |
可以看到, 当 outbound 事件(这里是 connect 事件)传递到 Pipeline 后, 它其实是以 tail为起点开始传播的.
而 tail.connect 其实调用的是 AbstractChannelHandlerContext.connect 方法:
1 | public ChannelFuture connect( |
findContextOutbound() 顾名思义, 它的作用是以当前 Context 为起点, 向 Pipeline 中的
Context 双向链表的前端寻找第一个 outbound 属性为真的 Context(即关联着
ChannelOutboundHandler 的 Context), 然后返回.
它的实现如下:
1 | private AbstractChannelHandlerContext findContextOutbound() { |
当我们找到了一个 outbound 的 Context 后, 就调用它的 invokeConnect 方法, 这个方法中
会调用 Context 所关联着的 ChannelHandler 的 connect 方法:
1 | private void invokeConnect(SocketAddress remoteAddress, SocketAddress localAddress, |
如果用户没有重写 ChannelHandler 的 connect 方法, 那么会调用
ChannelOutboundHandlerAdapter 所实现的方法:
1 | public void connect(ChannelHandlerContext ctx, SocketAddress remoteAddress, |
我们看到, ChannelOutboundHandlerAdapter.connect 仅仅调用了 ctx.connect, 而这个调用
又回到了:
Context.connect -> Connect.findContextOutbound -> next.invokeConnect ->
handler.connect -> Context.connect
这样的循环中, 直到 connect 事件传递到 DefaultChannelPipeline 的双向链表的头节点, 即
head 中. 为什么会传递到 head 中呢? 回想一下, head 实现了 ChannelOutboundHandler, 因
此它的 outbound 属性是 true.
因为 head 本身既是一个 ChannelHandlerContext, 又实现了 ChannelOutboundHandler 接口,
因此当 connect 消息传递到 head 后, 会将消息转递到对应的 ChannelHandler 中处理, 而恰
好, head 的 handler() 返回的就是 head 本身:
1 | public ChannelHandler handler() { |
因此最终 connect 事件是在 head 中处理的. head 的 connect 事件处理方法如下:
1 | public void connect( |
到这里, 整个 Connect 请求事件就结束了.
下面以一幅图来描述一个整个 Connect 请求事件的处理过程:
我们仅仅以 Connect 请求事件为例, 分析了 Outbound 事件的传播过程, 但是其实所有的
outbound 的事件传播都遵循着一样的传播规律,同学们可以试着分析一下其他的 outbound 事件, 体会一下它们的传播过程.
Inbound事件
Inbound 事件和 Outbound 事件的处理过程有点像.
Inbound 事件是一个通知事件, 即某件事已经发生了, 然后通过 Inbound 事件进行通知.
Inbound 通常发生在 Channel 的状态的改变或 IO 事件就绪.
Inbound 的特点是它传播方向是 head -> customContext -> tail.
既然上面我们分析了 Connect 这个 Outbound 事件, 那么接着分析 Connect 事件后会发生什
么 Inbound 事件, 并最终找到 Outbound 和 Inbound 事件之间的联系.
当 Connect 这个 Outbound 传播到 unsafe 后, 其实是在 AbstractNioUnsafe.connect 方法中进行处理的:
1 | public final void connect( |
在 AbstractNioUnsafe.connect 中, 首先调用 doConnect 方法进行实际上的 Socket 连接,
当连接上后, 会调用 fulfillConnectPromise 方法:
1 | private void fulfillConnectPromise(ChannelPromise promise, boolean wasActive) { |
我们看到, 在 fulfillConnectPromise 中, 会通过调用 pipeline().fireChannelActive() 将
通道激活的消息(即 Socket 连接成功)发送出去.
而这里, 当调用 pipeline.fireXXX 后, 就是 Inbound 事件的起点.
因此当调用了 pipeline().fireChannelActive() 后, 就产生了一个 ChannelActive Inbound
事件, 我们就从这里开始看看这个 Inbound 事件是怎么传播的吧.
1 | public final ChannelPipeline fireChannelActive() { |
果然, 在 fireChannelActive 方法中, 调用的是 head. invokeChannelActive , 因此可
以证明了, Inbound 事件在 Pipeline 中传输的起点是 head.那么, 在
head. invokeChannelActive () 中又做了什么呢?
1 | static void invokeChannelActive(final AbstractChannelHandlerContext next) { |
上面的代码应该很熟悉了吧. 回想一下在 Outbound 事件(例如 Connect 事件)的传输过程中时,我们也有类似的操作:
- 首先调用 findContextInbound, 从 Pipeline 的双向链表中中找到第一个属性 inbound为真的 Context, 然后返回
- 调用这个 Context 的 invokeChannelActive invokeChannelActive 方法如下:
1 | private void invokeChannelActive() { |
这个方法和 Outbound 的对应方法(例如 invokeConnect) 如出一辙. 同 Outbound 一样, 如果
用户没有重写 channelActive 方法, 那么会调用 ChannelInboundHandlerAdapter 的
channelActive 方法:
1 | public void channelActive(ChannelHandlerContext ctx) throws Exception { |
同样地, 在 ChannelInboundHandlerAdapter.channelActive 中, 仅仅调用了
ctx.fireChannelActive 方法, 因此就会有如下循环:
Context.fireChannelActive -> Connect.findContextInbound ->
nextContext.invokeChannelActive -> nextHandler.channelActive ->
nextContext.fireChannelActive
这样的循环中. 同理, tail 本身 既实现了 ChannelInboundHandler 接口, 又实现了
ChannelHandlerContext 接口, 因此当 channelActive 消息传递到 tail 后, 会将消息转递到
对应的 ChannelHandler 中处理, 而恰好, tail 的 handler() 返回的就是 tail 本身:
1 | public ChannelHandler handler() { |
因此 channelActive Inbound 事件最终是在 tail 中处理的, 我们看一下它的处理方法:
1 | public void channelActive(ChannelHandlerContext ctx) throws Exception {} |
TailContext.channelActive 方法是空的. 如果读者自行查看 TailContext 的 Inbound 处理
方法时, 会发现, 它们的实现都是空的. 可见, 如果是 Inbound, 当用户没有实现自定义的处理器时, 那么默认是不处理的.
用一幅图来总结一下 Inbound 的传输过程吧:
总结
对于Outbound事件
- Outbound 事件是请求事件(由 Connect 发起一个请求, 并最终由 unsafe 处理这个请求)
- Outbound 事件的发起者是 Channel
- Outbound 事件的处理者是 unsafe
- Outbound 事件在 Pipeline 中的传输方向是 tail -> head.
- 在 ChannelHandler 中处理事件时, 如果这个 Handler 不是最后一个 Hnalder, 则需要调用 ctx.xxx (例如 ctx.connect) 将此事件继续传播下去. 如果不这样做, 那么此事件的传播会提前终止.
- Outbound 事件流: Context.OUT_EVT -> Connect.findContextOutbound ->nextContext.invokeOUT_EVT -> nextHandler.OUT_EVT -> nextContext.OUT_EVT
对于Inbound事件
- Inbound 事件是通知事件, 当某件事情已经就绪后, 通知上层.
- Inbound 事件发起者是 unsafe
- Inbound 事件的处理者是 Channel, 如果用户没有实现自定义的处理方法, 那么Inbound 事件默认的处理者是 TailContext, 并且其处理方法是空实现.
- Inbound 事件在 Pipeline 中传输方向是 head -> tail
- 在 ChannelHandler 中处理事件时, 如果这个 Handler 不是最后一个 Hnalder, 则需要调用 ctx.fireIN_EVT (例如 ctx.fireChannelActive) 将此事件继续传播下去. 如果不这样做,那么此事件的传播会提前终止.
- Outbound 事件流: Context.fireIN_EVT -> Connect.findContextInbound ->nextContext.invokeIN_EVT -> nextHandler.IN_EVT -> nextContext.fireIN_EVT outbound 和 inbound 事件十分的像, 并且 Context 与 Handler 直接的调用关系是否容易混淆, 因此我们在阅读这里的源码时, 需要特别的注意.
EventLoop
前面的章节中我们已经知道了, 一个 Netty 程序启动时, 至少要指定一个 EventLoopGroup(如
果使用到的是 NIO, 那么通常是 NioEventLoopGroup), 那么这个 NioEventLoopGroup 在
Netty 中到底扮演着什么角色呢? 我们知道, Netty 是 Reactor 模型的一个实现, 那么首先从
Reactor 的线程模型开始吧.
关于Reactor的线程模型
首先我们来看一下 Reactor 的线程模型.
Reactor 的线程模型有三种:
- 单线程模型
- 多线程模型
- 主从多线程模型
首先来看一下 单线程模型: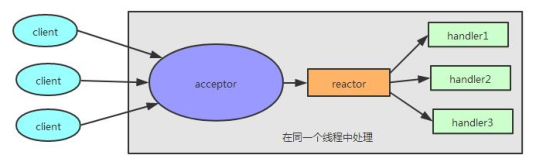
所谓单线程, 即 acceptor 处理和 handler 处理都在一个线程中处理. 这个模型的坏处显而易
见: 当其中某个 handler 阻塞时, 会导致其他所有的 client 的 handler 都得不到执行, 并
且更严重的是, handler 的阻塞也会导致整个服务不能接收新的 client 请求(因为 acceptor
也被阻塞了). 因为有这么多的缺陷, 因此单线程 Reactor 模型用的比较少.
那么什么是 多线程模型 呢? Reactor 的多线程模型与单线程模型的区别就是 acceptor 是一
个单独的线程处理, 并且有一组特定的 NIO 线程来负责各个客户端连接的 IO 操作. Reactor
多线程模型如下: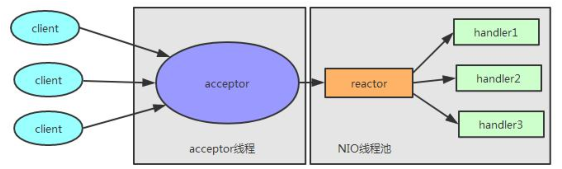
Reactor 多线程模型 有如下特点:
- 有专门一个线程, 即 Acceptor 线程用于监听客户端的 TCP 连接请求.
- 客户端连接的 IO 操作都是由一个特定的 NIO 线程池负责. 每个客户端连接都与一个特定的 NIO 线程绑定, 因此在这个客户端连接中的所有 IO 操作都是在同一个线程中完成的.
- 客户端连接有很多, 但是 NIO 线程数是比较少的, 因此一个 NIO 线程可以同时绑定到多个客户端连接中.
接下来我们再来看一下 Reactor 的主从多线程模型.
一般情况下, Reactor 的多线程模式已经可以很好的工作了, 但是我们考虑一下如下情况:
如果我们的服务器需要同时处理大量的客户端连接请求或我们需要在客户端连接时, 进行一些
权限的检查, 那么单线程的 Acceptor 很有可能就处理不过来, 造成了大量的客户端不能连接
到服务器.Reactor 的主从多线程模型就是在这样的情况下提出来的, 它的特点是: 服务器端接收客
户端的连接请求不再是一个线程, 而是由一个独立的线程池组成. 它的线程模型如下: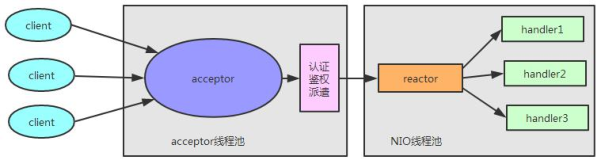
可以看到, Reactor 的主从多线程模型和 Reactor 多线程模型很类似, 只不过 Reactor 的主
从多线程模型的 acceptor 使用了线程池来处理大量的客户端请求
NioEventLoopGroup 和 Reactor线程模型的对应
我们介绍了三种 Reactor 的线程模型, 那么它们和 NioEventLoopGroup 又有什么关系呢? 其
实, 不同的设置 NioEventLoopGroup 的方式就对应了不同的 Reactor 的线程模型.
单线程模型
来看一下下面的例子:
1 | EventLoopGroup bossGroup = new NioEventLoopGroup(1); |
注意, 我们实例化了一个 NioEventLoopGroup, 然后接着我们调用 server.group(bossGroup)
设置了服务器端的 EventLoopGroup. 有人可能会有疑惑: 我记得在启动服务器端的 Netty 程
序时, 是需要设置 bossGroup 和 workerGroup 的, 为什么这里就只有一个 bossGroup?
其实很简单, ServerBootstrap 重写了 group 方法:
1 | public ServerBootstrap group(EventLoopGroup group) { |
因此当传入一个 group 时, 那么 bossGroup 和 workerGroup 就是同一个 NioEventLoopGroup
了.
这时候呢, 因为 bossGroup 和 workerGroup 就是同一个 NioEventLoopGroup, 并且这个
NioEventLoopGroup 只有一个线程, 这样就会导致 Netty 中的 acceptor 和后续的所有客户端
连接的 IO 操作都是在一个线程中处理的. 那么对应到 Reactor 的线程模型中, 我们这样设置
NioEventLoopGroup 时, 就相当于 Reactor 单线程模型.
多线程模型
同理, 再来看一下下面的例子:
1 | EventLoopGroup bossGroup = new NioEventLoopGroup(128); |
将 bossGroup 的参数就设置为大于 1 的数,其实就是 Reactor 多线程模型
主从线程模型
相信同学们都想到了, 实现主从线程模型的例子如下:
1 | EventLoopGroup bossGroup = new NioEventLoopGroup(); |
bossGroup 为主线程, 而 workerGroup 中的线程是 CPU 核心数乘以 2, 因此对应的到
Reactor 线程模型中, 我们知道, 这样设置的 NioEventLoopGroup 其实就是 Reactor 主从多
线程模型.
NioEventLoopGroup类层次结构
NioEventLoopGroup实例化过程
在前面的章节中我们已经简单地介绍了一下 NioEventLoopGroup 的初始化过程, 这里再回顾一下: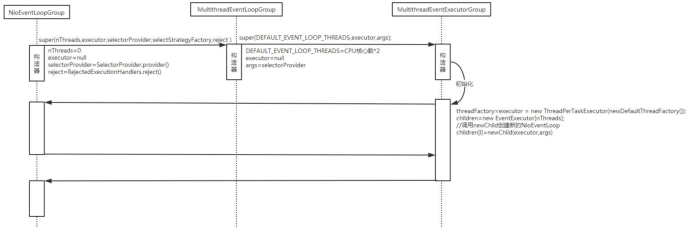
即:
- EventLoopGroup(其实是 MultithreadEventExecutorGroup) 内部维护一个类型为
EventExecutor children 数组, 其大小是 nThreads, 这样就构成了一个线程池 - 如果我们在实例化 NioEventLoopGroup 时, 如果指定线程池大小, 则 nThreads 就是指
定的值, 反之是处理器核心数 * 2 - MultithreadEventExecutorGroup 中会调用 newChild 抽象方法来初始化 children 数组
- 抽象方法 newChild 是在 NioEventLoopGroup 中实现的, 它返回一个 NioEventLoop 实
例. - NioEventLoop 属性:
- SelectorProvider provider 属 性 : NioEventLoopGroup 构 造 器 中 通 过SelectorProvider.provider() 获取一个 SelectorProvider
- Selector selector 属 性: NioEventLoop 构 造器 中 通过 调 用通 过 selector =provider.openSelector() 获取一个 selector 对象.
NioEventLoop类层次结构
NioEventLoop 继 承 于 SingleThreadEventLoop, 而 SingleThreadEventLoop 又 继 承 于
SingleThreadEventExecutor. SingleThreadEventExecutor 是 Netty 中对本地线程的抽象,
它内部有一个 Thread thread 属性, 存储了一个本地 Java 线程. 因此我们可以认为, 一个
NioEventLoop 其实和一个特定的线程绑定, 并且在其生命周期内, 绑定的线程都不会再改变.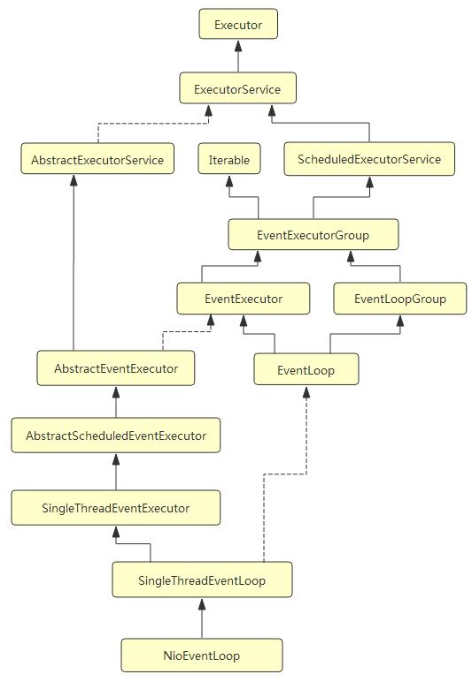
NioEventLoop 的类层次结构图还是比较复杂的, 不过我们只需要关注几个重要的点即可. 首先
NioEventLoop 的继承链如下:
NioEventLoop -> SingleThreadEventLoop -> SingleThreadEventExecutor ->
AbstractScheduledEventExecutor
在 AbstractScheduledEventExecutor 中, Netty 实现了 NioEventLoop 的 schedule 功能,
即我们可以通过调用一个 NioEventLoop 实例的 schedule 方法来运行一些定时任务. 而在
SingleThreadEventLoop 中, 又实现了任务队列的功能, 通过它, 我们可以调用一个
NioEventLoop 实例的 execute 方法来向任务队列中添加一个 task, 并由 NioEventLoop 进行
调度执行.
通常来说, NioEventLoop 肩负着两种任务, 第一个是作为 IO 线程, 执行与 Channel 相关的
IO 操作, 包括 调用 select 等待就绪的 IO 事件、读写数据与数据的处理等; 而第二个任务是
作为任务队列, 执行 taskQueue 中的任务, 例如用户调用 eventLoop.schedule 提交的定时任
务也是这个线程执行的.
NioEventLoop的实例化过程
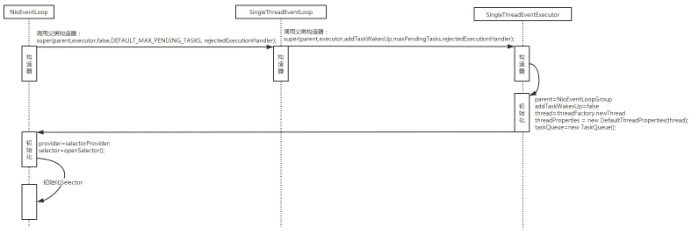
从上图可以看到, SingleThreadEventExecutor 有一个名为 thread 的 Thread 类型字段, 这
个字段就代表了与 SingleThreadEventExecutor 关联的本地线程.
我们看看 thread 在哪里赋的值:
1 | private void doStartThread() { |
SingleThreadEventExecutor 启动时会调用 doStartThread 方法,然后执行 executor.execute 方
法 , 将 当 前 线 程 赋 值 给 thread. 在 这 个 线 程 中 所 做 的 事 情 主 要 就 是 调 用
SingleThreadEventExecutor.this.run() 方法, 而因为 NioEventLoop 实现了这个方法, 因此
根据多态性, 其实调用的是 NioEventLoop.run() 方法.
EventLoop 与 Channel的关联
Netty 中, 每个 Channel 都有且仅有一个 EventLoop 与之关联, 它们的关联过程如下: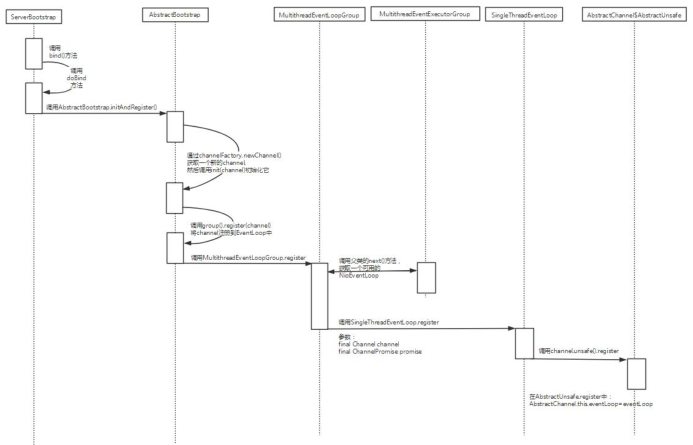
从上图中我们可以看到, 当调用了 AbstractChannel$AbstractUnsafe.register 后, 就完成了
Channel 和 EventLoop 的关联. register 实现如下:
1 | public final void register(EventLoop eventLoop, final ChannelPromise promise) { |
在 AbstractChannel$AbstractUnsafe.register 中 , 会 将 一 个 EventLoop 赋 值 给
AbstractChannel 内部的 eventLoop 字段, 到这里就完成了 EventLoop 与 Channel 的关联过程.
EventLoop的启动
在前面我们已经知道了, NioEventLoop 本身就是一个 SingleThreadEventExecutor, 因此
NioEventLoop 的启动, 其实就是 NioEventLoop 所绑定的本地 Java 线程的启动.
依照这个思想, 我们只要找到在哪里调用了 SingleThreadEventExecutor 的 thread 字段的
start() 方法就可以知道是在哪里启动的这个线程了.
从代码中搜索, thread.start() 被封装到 SingleThreadEventExecutor.startThread() 方法
中了:
1 | private void startThread() { |
STATE_UPDATER 是 SingleThreadEventExecutor 内部维护的一个属性, 它的作用是标识当前的
thread 的状态. 在初始的时候, STATE_UPDATER == ST_NOT_STARTED, 因此第一次调用
startThread() 方法时, 就会进入到 if 语句内, 进而调用到 thread.start().
而这个关键的 startThread() 方法又是在哪里调用的呢? 经过方法调用关系搜索, 我们发现,
startThread 是在 SingleThreadEventExecutor.execute 方法中调用的:
1 | public void execute(Runnable task) { |
既 然 如 此 , 那 现 在 我 们 的 工 作 就 变 为 了 寻 找 在 哪 里 第 一 次 调 用 了
SingleThreadEventExecutor.execute() 方法.
如果留心的同学可能已经注意到了, 我们在前面 EventLoop 与 Channel 的关联 这一小节时,
有提到到在注册 channel 的过程中, 会在 AbstractChannelAbstractUnsafe.register 部分代码如下:
1 | public final void register(EventLoop eventLoop, final ChannelPromise promise) { |
很显然, 一路从 Bootstrap.bind 方法跟踪到 AbstractChannel$AbstractUnsafe.register 方
法, 整个代码都是在主线程中运行的, 因此上面的 eventLoop.inEventLoop() 就为 false, 于
是 进入 到 else 分 支, 在 这个 分 支 中调 用 了 eventLoop.execute. eventLoop 是 一个
NioEventLoop 的 实 例 , 而 NioEventLoop 没 有 实 现 execute 方 法 , 因 此 调 用 的 是
SingleThreadEventExecutor.execute:
1 | public void execute(Runnable task) { |
我们已经分析过了, inEventLoop == false, 因此执行到 else 分支, 在这里就调用了
startThread() 方法来启动 SingleThreadEventExecutor 内部关联的 Java 本地线程了.
总结一句话, 当 EventLoop.execute 第一次被调用时, 就会触发 startThread() 的调用, 进
而导致了 EventLoop 所对应的 Java 线程的启动.
我们将 EventLoop 与 Channel 的关联 小节中的时序图补全后, 就得到了 EventLoop 启动过程的时序图: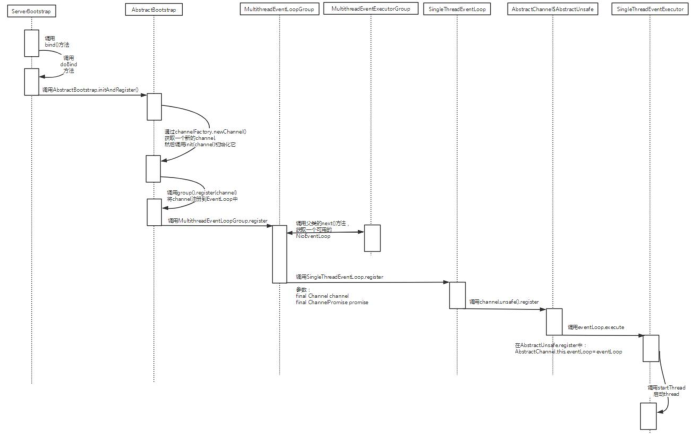
Promise与Future
java.util.concurrent.Future 是 Java 提供的接口,表示异步执行的状态,Future 的 get 方法
会判断任务是否执行完成,如果完成就返回结果,否则阻塞线程,直到任务完成。
Netty 扩展了 Java 的 Future,最主要的改进就是增加了监听器 Listener 接口,通过监听器可以
让异步执行更加有效率,不需要通过 get 来等待异步执行结束,而是通过监听器回调来精确地控
制异步执行结束的时间点。
1 | public interface Future<V> extends java.util.concurrent.Future<V> { |
ChannelFuture 接口扩展了 Netty 的 Future 接口,表示一种没有返回值的异步调用,同时关联
了 Channel,跟一个 Channel 绑定
1 | public interface ChannelFuture extends Future<Void> { |
Promise 接口也扩展了 Future 接口,它表示一种可写的 Future,就是可以设置异步执行的结果
1 | public interface Promise<V> extends Future<V> { |
ChannelPromise 接口扩展了 Promise 和 ChannelFuture,绑定了 Channel,又可写异步执行结构,
又具备了监听者的功能,是 Netty 实际编程使用的表示异步执行的接口
1 | public interface ChannelPromise extends ChannelFuture, Promise<Void> { |
DefaultChannelPromise 是 ChannelPromise 的实现类,它是实际运行时的 Promoise 实例。
Netty 使用 addListener 的方式来回调异步执行的结果。
看一下 DefaultPromise 的 addListener 方法,它判断异步任务执行的状态,如果执行完成,就
理解通知监听者,否则加入到监听者队列通知监听者就是找一个线程来执行调用监听的回调函数。
1 | public Promise<V> addListener(GenericFutureListener<? extends Future<? super V>> |
再来看监听者的接口,就一个方法,即等异步任务执行完成后,拿到 Future 结果,执行回调的逻辑
1 | public interface GenericFutureListener<F extends Future<?>> extends EventListener { |
Handler的各种姿势
ChannelHandlerContext
每个 ChannelHandler 被添加到 ChannelPipeline 后,都会创建一个 ChannelHandlerContext 并
与之创建的 ChannelHandler 关联绑定。ChannelHandlerContext 允许 ChannelHandler 与其他的
ChannelHandler 实 现 进 行 交 互 。 ChannelHandlerContext 不 会 改 变 添 加 到 其 中 的
ChannelHandler,因此它是安全的。
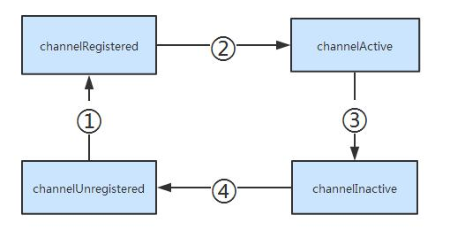
Channel的状态模型
Netty 有一个简单但强大的状态模型,并完美映射到 ChannelInboundHandler 的各个方法。下面
是 Channel 生命周期四个不同的状态:
- channelUnregistered
- channelRegistered
- channelActive
- channelInactive
Channel 的状态在其生命周期中变化,因为状态变化需要触发,下图显示了 Channel 状态变化:![]()
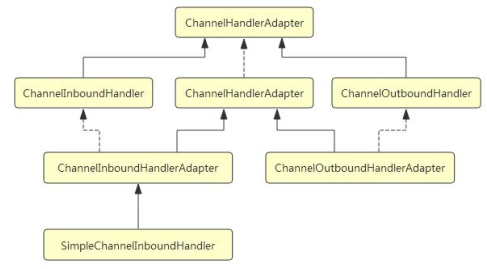
ChannelHandler和其子类
ChannelHandler中的方法
Netty 定义了良好的类型层次结构来表示不同的处理程序类型,所有的类型的父类是
ChannelHandler。ChannelHandler 提供了在其生命周期内添加或从 ChannelPipeline 中删除的方法。
- handlerAdded,ChannelHandler 添加到实际上下文中准备处理事件
- handlerRemoved,将 ChannelHandler 从实际上下文中删除,不再处理事件
- exceptionCaught,处理抛出的异常
Netty 还 提 供 了 一 个 实 现 了 ChannelHandler 的 抽 象 类 ChannelHandlerAdapter 。
ChannelHandlerAdapter 实现了父类的所有方法,基本上就是传递事件到 ChannelPipeline 中的
下一个 ChannelHandler 直到结束。我们也可以直接继承于 ChannelHandlerAdapter,然后重写
里面的方法。
ChannelInboundHandler
ChannelInboundHandler 提供了一些方法再接收数据或 Channel 状态改变时被调用。下面是
ChannelInboundHandler 的一些方法:
- channelRegistered,ChannelHandlerContext 的 Channel 被注册到 EventLoop;
- channelUnregistered,ChannelHandlerContext 的 Channel 从 EventLoop 中注销
- channelActive,ChannelHandlerContext 的 Channel 已激活
- channelInactive,ChannelHanderContxt 的 Channel 结束生命周期
- channelRead,从当前 Channel 的对端读取消息
- channelReadComplete,消息读取完成后执行
- userEventTriggered,一个用户事件被触发
- channelWritabilityChanged,改变通道的可写状态,可以使用 Channel.isWritable()检查
- exceptionCaught,重写父类 ChannelHandler 的方法,处理异常
Netty 提供了一个实现了 ChannelInboundHandler 接口并继承 ChannelHandlerAdapter 的类:
ChannelInboundHandlerAdapter 。 ChannelInboundHandlerAdapter 实 现 了
ChannelInboundHandler 的所有方法,作用就是处理消息并将消息转发到 ChannelPipeline 中的
下一个 ChannelHandler。ChannelInboundHandlerAdapter 的 channelRead 方法处理完消息后不
会自动释放消息,若想自动释放收到的消息,可以使用 SimpleChannelInboundHandler。
看下面的代码:
1 | public class UnreleaseHandler extends ChannelInboundHandlerAdapter { |
SimpleChannelInboundHandler 会自动释放消息
1 | public class ReleaseHandler extends SimpleChannelInboundHandler<Object> { |
ChannelInitializer 用来初始化 ChannelHandler,将自定义的各种 ChannelHandler 添加到ChannelPipeline 中。
编码和解码
Tcp粘包和拆包
TCP 是一个“流”协议,所谓流,就是没有界限的一长串二进制数据。TCP 作为传输层协议并不
不了解上层业务数据的具体含义,它会根据 TCP 缓冲区的实际情况进行数据包的划分,所以在业
务上认为是一个完整的包,可能会被 TCP 拆分成多个包进行发送,也有可能把多个小的包封装成
一个大的数据包发送,这就是所谓的 TCP 粘包和拆包问题。
粘包问题的解决策略
由于底层的 TCP 无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这
个问题只能通过上层的应用协议栈设计来解决。业界的主流协议的解决方案,可以归纳如下:
- 消息定长,报文大小固定长度,例如每个报文的长度固定为 200 字节,如果不够空位补空格;
- 包尾添加特殊分隔符,例如每条报文结束都添加回车换行符(例如 FTP 协议)或者指定特殊
字符作为报文分隔符,接收方通过特殊分隔符切分报文区分; - 将消息分为消息头和消息体,消息头中包含表示信息的总长度(或者消息体长度)的字段;
- 更复杂的自定义应用层协议。
编码和解码技术
通常我们也习惯将编码(Encode)称为序列化(serialization),它将对象序列化为字节数组,
用于网络传输、数据持久化或者其它用途。
反之,解码(Decode)/反序列化(deserialization)把从网络、磁盘等读取的字节数组还原成
原始对象(通常是原始对象的拷贝),以方便后续的业务逻辑操作。
进行远程跨进程服务调用时(例如 RPC 调用),需要使用特定的编解码技术,对需要进行网络传
输的对象做编码或者解码,以便完成远程调用。
Netty为什么要提交编码解码框架
作为一个高性能的异步、NIO 通信框架,编解码框架是 Netty 的重要组成部分。尽管站在微内核
的角度看,编解码框架并不是 Netty 微内核的组成部分,但是通过 ChannelHandler 定制扩展出
的编解码框架却是不可或缺的。
然而,我们已经知道在 Netty 中,从网络读取的 Inbound 消息,需要经过解码,将二进制的数据
报转换成应用层协议消息或者业务消息,才能够被上层的应用逻辑识别和处理;同理,用户发送
到网络的 Outbound 业务消息,需要经过编码转换成二进制字节数组(对于 Netty 就是 ByteBuf)
才能够发送到网络对端。编码和解码功能是 NIO 框架的有机组成部分,无论是由业务定制扩展实
现,还是 NIO 框架内置编解码能力,该功能是必不可少的。
为了降低用户的开发难度,Netty 对常用的功能和 API 做了装饰,以屏蔽底层的实现细节。编解
码功能的定制,对于熟悉 Netty 底层实现的开发者而言,直接基于 ChannelHandler 扩展开发,
难度并不是很大。但是对于大多数初学者或者不愿意去了解底层实现细节的用户,需要提供给他
们更简单的类库和 API,而不是 ChannelHandler。
Netty 在这方面做得非常出色,针对编解码功能,它既提供了通用的编解码框架供用户扩展,又
提供了常用的编解码类库供用户直接使用。在保证定制扩展性的基础之上,尽量降低用户的开发
工作量和开发门槛,提升开发效率。
Netty 预置的编解码功能列表如下:base64、Protobuf、JBoss Marshalling、spdy 等。
Netty粘包和拆包解决方案
Netty中常用的解码器
Netty 提供了多个解码器,可以进行分包的操作,分别是:
- LineBasedFrameDecoder
- DelimiterBasedFrameDecoder(添加特殊分隔符报文来分包)
- FixedLengthFrameDecoder(使用定长的报文来分包)
- LengthFieldBasedFrameDecoder
LineBasedFrameDecoder 解码器
LineBasedFrameDecoder 是回车换行解码器,如果用户发送的消息以回车换行符作为消息结束的
标识,则可以直接使用 Netty 的 LineBasedFrameDecoder 对消息进行解码,只需要在初始化 Netty
服务端或者客户端时将 LineBasedFrameDecoder 正确的添加到 ChannelPipeline 中即可,不需要
自己重新实现一套换行解码器。
LineBasedFrameDecoder 的工作原理是它依次遍历 ByteBuf 中的可读字节,判断看是否有“\n”
或者“\r\n”,如果有,就以此位置为结束位置,从可读索引到结束位置区间的字节就组成了一
行。它是以换行符为结束标志的解码器,支持携带结束符或者不携带结束符两种解码方式,同时
支持配置单行的最大长度。如果连续读取到最大长度后仍然没有发现换行符,就会抛出异常,同
时忽略掉之前读到的异常码流。防止由于数据报没有携带换行符导致接收到 ByteBuf 无限制积
压,引起系统内存溢出。
它的使用效果如下:
通常情况下,LineBasedFrameDecoder 会和 StringDecoder 配合使用,组合成按行切换的文本解
码器,对于文本类协议的解析,文本换行解码器非常实用,例如对 HTTP 消息头的解析、FTP 协
议消息的解析等。
下面我们简单给出文本换行解码器的使用示例:
1 | pipeline.addLast(new LineBasedFrameDecoder(1024)); |
初始化 Channel 的时候,首先将 LineBasedFrameDecoder 添加到 ChannelPipeline 中,然后再依
次添加字符串解码器 StringDecoder,业务 Handler。
DelimiterBasedFrameDecoder 解码器
DelimiterBasedFrameDecoder 是分隔符解码器,用户可以指定消息结束的分隔符,它可以自动
完成以分隔符作为码流结束标识的消息的解码。回车换行解码器实际上是一种特殊的
DelimiterBasedFrameDecoder 解码器。
分隔符解码器在实际工作中也有很广泛的应用,笔者所从事的电信行业,很多简单的文本私有协
议,都是以特殊的分隔符作为消息结束的标识,特别是对于那些使用长连接的基于文本的私有协
议。
分隔符的指定:与大家的习惯不同,分隔符并非以 char 或者 string 作为构造参数,而是 ByteBuf,
下面我们就结合实际例子给出它的用法。
假如消息以“$_”作为分隔符,服务端或者客户端初始化 ChannelPipeline 的代码实例如下:
1 | ByteBuf delimiter = Unpooled.copiedBuffer("$_".getBytes()); |
首先将$_转换成 ByteBuf 对象,作为参数构造 DelimiterBasedFrameDecoder,将其添加到
ChannelPipeline 中,然后依次添加字符串解码器(通常用于文本解码)和用户 Handler,请注
意解码器和 Handler 的添加顺序,如果顺序颠倒,会导致消息解码失败。
DelimiterBasedFrameDecoder 原理分析:解码时,判断当前已经读取的 ByteBuf 中是否包含分
隔符 ByteBuf,如果包含,则截取对应的 ByteBuf 返回,源码如下:
1 | protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception { |
详细分析下 indexOf(buffer, delim)方法的实现,代码如下:
1 | private static int indexOf(ByteBuf haystack, ByteBuf needle) { |
该算法与 Java String 中的搜索算法类似,对于原字符串使用两个指针来进行搜索,如果搜索成
功,则返回索引位置,否则返回-1。
FixedLengthFrameDecoder 解码器
FixedLengthFrameDecoder 是固定长度解码器,它能够按照指定的长度对消息进行自动解码,开
发者不需要考虑 TCP 的粘包/拆包等问题,非常实用。
对于定长消息,如果消息实际长度小于定长,则往往会进行补位操作,它在一定程度上导致了空
间和资源的浪费。但是它的优点也是非常明显的,编解码比较简单,因此在实际项目中仍然有一
定的应用场景。
利用 FixedLengthFrameDecoder 解码器,无论一次接收到多少数据报,它都会按照构造函数中设
置的固定长度进行解码,如果是半包消息,FixedLengthFrameDecoder 会缓存半包消息并等待下
个包到达后进行拼包,直到读取到一个完整的包。
假如单条消息的长度是 20 字节,使用 FixedLengthFrameDecoder 解码器的效果如下:
LengthFieldBasedFrameDecoder 解码器
了解 TCP 通信机制的该都知道 TCP 底层的粘包和拆包,当我们在接收消息的时候,显示不能认为
读取到的报文就是个整包消息,特别是对于采用非阻塞 I/O 和长连接通信的程序。
如何区分一个整包消息,通常有如下 4 种做法:
- 固定长度,例如每 120 个字节代表一个整包消息,不足的前面补位。解码器在处理这类定常消息的时候比较简单,每次读到指定长度的字节后再进行解码;
- 通过回车换行符区分消息,例如 HTTP 协议。这类区分消息的方式多用于文本协议;
- 通过特定的分隔符区分整包消息;
- 通过在协议头/消息头中设置长度字段来标识整包消息。
前三种解码器之前的章节已经做了详细介绍,下面让我们来一起学习最后一种通用解码器
-LengthFieldBasedFrameDecoder。
大多数的协议(私有或者公有),协议头中会携带长度字段,用于标识消息体或者整包消息的长
度,例如 SMPP、HTTP 协议等。由于基于长度解码需求的通用性,以及为了降低用户的协议开发
难度,Netty 提供了 LengthFieldBasedFrameDecoder,自动屏蔽 TCP 底层的拆包和粘包问题,只
需要传入正确的参数,即可轻松解决“读半包“问题。
下面我们看看如何通过参数组合的不同来实现不同的“半包”读取策略。第一种常用的方式是消
息的第一个字段是长度字段,后面是消息体,消息头中只包含一个长度字段。它的消息结构定义
如图所示: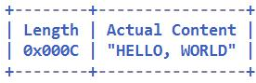
使用以下参数组合进行解码:
- lengthFieldOffset = 0;
- lengthFieldLength = 2;
- lengthAdjustment = 0;
- initialBytesToStrip = 0。
解码后的字节缓冲区内容如图所示:
通过 ByteBuf.readableBytes()方法我们可以获取当前消息的长度,所以解码后的字节缓冲区可
以不携带长度字段,由于长度字段在起始位置并且长度为 2,所以将 initialBytesToStrip 设置
为 2,参数组合修改为:
- lengthFieldOffset = 0;
- lengthFieldLength = 2;
- lengthAdjustment = 0;
- initialBytesToStrip = 2。
解码后的字节缓冲区内容如图所示:
解码后的字节缓冲区丢弃了长度字段,仅仅包含消息体,对于大多数的协议,解码之后消息长度
没有用处,因此可以丢弃。
在大多数的应用场景中,长度字段仅用来标识消息体的长度,这类协议通常由消息长度字段+消
息体组成,如上图所示的几个例子。但是,对于某些协议,长度字段还包含了消息头的长度。在
这种应用场景中,往往需要使用 lengthAdjustment 进行修正。由于整个消息(包含消息头)的
长度往往大于消息体的长度,所以,lengthAdjustment 为负数。图 2-6 展示了通过指定
lengthAdjustment 字段来包含消息头的长度:
- lengthFieldOffset = 0;
- lengthFieldLength = 2;
- lengthAdjustment = -2;
- initialBytesToStrip = 0。
解码之前的码流:![]()
解码之后的码流:![]()
由于协议种类繁多,并不是所有的协议都将长度字段放在消息头的首位,当标识消息长度的字段
位于消息头的中间或者尾部时,需要使用 lengthFieldOffset 字段进行标识,下面的参数组合给
出了如何解决消息长度字段不在首位的问题: - lengthFieldOffset = 2;
- lengthFieldLength = 3;
- lengthAdjustment = 0;
- initialBytesToStrip = 0。
其中 lengthFieldOffset 表示长度字段在消息头中偏移的字节数,lengthFieldLength 表示长度
字段自身的长度,解码效果如下:
解码之前:![]()
解码之后:![]()
由于消息头 1 的长度为 2,所以长度字段的偏移量为 2;消息长度字段 Length 为 3,所以
lengthFieldLength 值为 3。由于长度字段仅仅标识消息体的长度,所以 lengthAdjustment 和
initialBytesToStrip 都为 0。
最后一种场景是长度字段夹在两个消息头之间或者长度字段位于消息头的中间,前后都有其它消
息头字段,在这种场景下如果想忽略长度字段以及其前面的其它消息头字段,则可以通过
initialBytesToStrip 参数来跳过要忽略的字节长度,它的组合配置示意如下: - lengthFieldOffset = 1;
- lengthFieldLength = 2;
- lengthAdjustment = 1;
- initialBytesToStrip = 3。
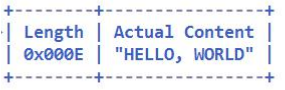



解码之前的码流(16 字节):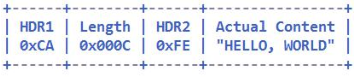
解码之后的码流(13 字节):
由于 HDR1 的长度为 1,所以长度字段的偏移量 lengthFieldOffset 为 1;长度字段为 2 个字节,
所以 lengthFieldLength 为 2。由于长度字段是消息体的长度,解码后如果携带消息头中的字段,
则需要使用 lengthAdjustment 进行调整,此处它的值为 1,代表的是 HDR2 的长度,最后由于解
码后的缓冲区要忽略长度字段和 HDR1 部分,所以 lengthAdjustment 为 3。解码后的结果为 13
个字节,HDR1 和 Length 字段被忽略。
事实上,通过 4 个参数的不同组合,可以达到不同的解码效果,用户在使用过程中可以根据业务
的实际情况进行灵活调整。
由于 TCP 存在粘包和组包问题,所以通常情况下用户需要自己处理半包消息。利用
LengthFieldBasedFrameDecoder 解码器可以自动解决半包问题,它的习惯用法如下:
1 | pipeline.addLast("frameDecoder", new LengthFieldBasedFrameDecoder(65536,0,2)); |
在 pipeline 中增加 LengthFieldBasedFrameDecoder 解码器,指定正确的参数组合,它可以将
Netty 的 ByteBuf 解码成整包消息,后面的用户解码器拿到的就是个完整的数据报,按照逻辑正
常进行解码即可,不再需要额外考虑“读半包”问题,降低了用户的开发难度。
Netty常用编码器
Netty 默认提供了丰富的编解码框架供用户集成使用,我们只对较常用的 Java 序列化编码器进
行讲解。其它的编码器,实现方式大同小异。
ObjectEncoder编码器
ObjectEncoder是Java序列化编码器,它负责将实现Serializable接口的对象序列化为byte [],
然后写入到 ByteBuf 中用于消息的跨网络传输。
下面我们一起分析下它的实现:
首先,我们发现它继承自 MessageToByteEncoder,它的作用就是将对象编码成 ByteBuf:
1 | public class ObjectEncoder extends MessageToByteEncoder<Serializable> |
如果要使用 Java 序列化,对象必须实现 Serializable 接口,因此,它的泛型类型为Serializable。
MessageToByteEncoder 的子类只需要实现 encode(ChannelHandlerContext ctx, I msg, ByteBuf out)方法即可,下面我们重点关注 encode 方法的实现:
1 | protected void encode(ChannelHandlerContext ctx, Serializable msg, ByteBuf out) throws |
首先创建 ByteBufOutputStream 和 ObjectOutputStream,用于将 Object 对象序列化到 ByteBuf
中,值得注意的是在 writeObject 之前需要先将长度字段(4 个字节)预留,用于后续长度字段
的更新。
依次写入长度占位符(4 字节)、序列化之后的 Object 对象,之后根据 ByteBuf 的 writeIndex
计算序列化之后的码流长度,最后调用 ByteBuf 的 setInt(int index, int value)更新长度占
位符为实际的码流长度。
有个细节需要注意,更新码流长度字段使用了 setInt 方法而不是 writeInt,原因就是 setInt
方法只更新内容,并不修改 readerIndex 和 writerIndex.
自定义编码和解码
尽管 Netty 预置了丰富的编解码类库功能,但是在实际的业务开发过程中,总是需要对编解码功
能做一些定制。使用 Netty 的编解码框架,可以非常方便的进行协议定制。本章节将对常用的支
持定制的编解码类库进行讲解,以期让读者能够尽快熟悉和掌握编解码框架。
ByteToMessageDecoder 抽象解码器
使用 NIO 进行网络编程时,往往需要将读取到的字节数组或者字节缓冲区解码为业务可以使用的
POJO 对象。为了方便业务将 ByteBuf 解码成业务 POJO 对象,Netty 提供了 ByteToMessageDecoder
抽象工具解码类。
用户自定义解码器继承 ByteToMessageDecoder,只需要实现 void decode(ChannelHandler
Context ctx, ByteBuf in, List
MessageToMessageDecoder 抽象解码器
MessageToMessageDecoder 实际上是 Netty 的二次解码器,它的职责是将一个对象二次解码为其
它对象。
为什么称它为二次解码器呢?我们知道,从 SocketChannel 读取到的 TCP 数据报是 ByteBuffer,
实际就是字节数组。我们首先需要将ByteBuffer缓冲区中的数据报读取出来,并将其解码为Java
对象;然后对 Java 对象根据某些规则做二次解码,将其解码为另一个 POJO 对象。因为
MessageToMessageDecoder 在 ByteToMessageDecoder 之后,所以称之为二次解码器。
二次解码器在实际的商业项目中非常有用,以 HTTP+XML 协议栈为例,第一次解码往往是将字节
数组解码成 HttpRequest 对象,然后对 HttpRequest 消息中的消息体字符串进行二次解码,将
XML 格式的字符串解码为 POJO 对象,这就用到了二次解码器。类似这样的场景还有很多,不再
一一枚举。
事实上,做一个超级复杂的解码器将多个解码器组合成一个大而全的 MessageToMessageDecoder
解码器似乎也能解决多次解码的问题,但是采用这种方式的代码可维护性会非常差。例如,如果
我们打算在 HTTP+XML 协议栈中增加一个打印码流的功能,即首次解码获取 HttpRequest 对象之
后打印 XML 格式的码流。如果采用多个解码器组合,在中间插入一个打印消息体的 Handler 即可,
不需要修改原有的代码;如果做一个大而全的解码器,就需要在解码的方法中增加打印码流的代
码,可扩展性和可维护性都会变差。
用户的解码器只需要实现 void decode(ChannelHandlerContext ctx, I msg, List
1 | public class IntegerEncoder extends MessageToByteEncoder<Integer> { |
它的实现原理如下:调用 write 操作时,首先判断当前编码器是否支持需要发送的消息,如果不
支持则直接透传;如果支持则判断缓冲区的类型,对于直接内存分配 ioBuffer(堆外内存),
对于堆内存通过 heapBuffer 方法分配,源码如下:
1 | public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws |
编码使用的缓冲区分配完成之后,调用 encode 抽象方法进行编码,方法定义如下:它由子类负责具体实现。
1 | protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception; |
编码完成之后,调用ReferenceCountUtil的release方法释放编码对象msg。对编码后的ByteBuf
进行以下判断:
- 如果缓冲区包含可发送的字节,则调用 ChannelHandlerContext 的 write 方法发送 ByteBuf;
- 如果缓冲区没有包含可写的字节,则需要释放编码后的 ByteBuf,写入一个空的 ByteBuf 到ChannelHandlerContext 中。
发送操作完成之后,在方法退出之前释放编码缓冲区 ByteBuf 对象。
MessageToMessageEncoder 抽象编码器
将一个 POJO 对象编码成另一个对象,以 HTTP+XML 协议为例,它的一种实现方式是:先将 POJO
对象编码成 XML 字符串,再将字符串编码为 HTTP 请求或者应答消息。对于复杂协议,往往需要
经历多次编码,为了便于功能扩展,可以通过多个编码器组合来实现相关功能。
用 户 的 解 码 器 继 承 MessageToMessageEncoder 解 码 器 , 实 现 void encode(Channel
HandlerContext ctx, I msg, List
1 | public class IntegerToStringEncoder extends MessageToMessageEncoder<Integer> { |
MessageToMessageEncoder 编码器的实现原理与之前分析的 MessageToByteEncoder 相似,唯一
的差别是它编码后的输出是个中间对象,并非最终可传输的 ByteBuf。
简单看下它的源码实现:创建 RecyclableArrayList 对象,判断当前需要编码的对象是否是编码
器可处理的类型,如果不是,则忽略,执行下一个 ChannelHandler 的 write 方法。
具体的编码方法实现由用户子类编码器负责完成,如果编码后的 RecyclableArrayList 为空,说
明编码没有成功,释放 RecyclableArrayList 引用。
如果编码成功,则通过遍历 RecyclableArrayList,循环发送编码后的 POJO 对象,代码如下所示:
1 | public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws |
LengthFieldPrepender 编码器
如果协议中的第一个字段为长度字段,Netty 提供了 LengthFieldPrepender 编码器,它可以计
算当前待发送消息的二进制字节长度,将该长度添加到 ByteBuf 的缓冲区头中,如图所示: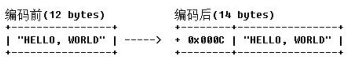
通过 LengthFieldPrepender 可以将待发送消息的长度写入到 ByteBuf 的前 2 个字节,编码后的
消息组成为长度字段+原消息的方式。
通过设置 LengthFieldPrepender 为 true,消息长度将包含长度本身占用的字节数,打开
LengthFieldPrepender 后,图 3-3 示例中的编码结果如下图所示: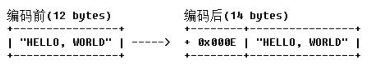
LengthFieldPrepender 工作原理分析如下:首先对长度字段进行设置,如果需要包含消息长度
自身,则在原来长度的基础之上再加上 lengthFieldLength 的长度。
如果调整后的消息长度小于 0,则抛出参数非法异常。对消息长度自身所占的字节数进行判断,
以便采用正确的方法将长度字段写入到 ByteBuf 中,共有以下 6 种可能:
- 长度字段所占字节为 1:如果使用 1 个 Byte 字节代表消息长度,则最大长度需要小于 256 个字节。对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的 ByteBuf并通过 writeByte 将长度值写入到 ByteBuf 中;
- 长度字段所占字节为 2:如果使用 2 个 Byte 字节代表消息长度,则最大长度需要小于 65536个字节,对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的 ByteBuf并通过 writeShort 将长度值写入到 ByteBuf 中;
- 长度字段所占字节为3:如果使用3个Byte字节代表消息长度,则最大长度需要小于16777216个字节,对长度进行校验,如果校验失败,则抛出参数非法异常;若校验通过,则创建新的 ByteBuf并通过 writeMedium 将长度值写入到 ByteBuf 中;
- 长度字段所占字节为 4:创建新的 ByteBuf,并通过 writeInt 将长度值写入到 ByteBuf 中;
- 长度字段所占字节为 8:创建新的 ByteBuf,并通过 writeLong 将长度值写入到 ByteBuf 中;
- 其它长度值:直接抛出 Error。相关代码如下:
1 | protected void encode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws |